預備
library(tidyverse)包(Package)
- 為何要用其他的包,base R 不是也有嗎?比如畫圖,R base 有
plot()、boxplot()等。為何要用ggplot2()?
為了彌補之前的漏洞,如果輕易的更動 base, 會癱瘓過去做過的成品。為了避免類似的狀況,所以開發新的方法。
包會整合容易混淆的作法,更一致的表達如何操作。
可是這樣講還是很模糊,要講清楚變成講古。總之我們已經沒必要追究過去怎麼做,只需要與時俱進,學習最新的方法即可。
- 為何選
tidyverse?
在呼叫 tidyverse 的時候會看到下面的資訊:
library(tidyverse)#> -- Attaching packages --------------------------------------- tidyverse 1.3.0 --#> √ ggplot2 3.3.3 √ purrr 0.3.4
#> √ tibble 3.0.6 √ dplyr 1.0.4
#> √ tidyr 1.1.2 √ stringr 1.4.0
#> √ readr 1.4.0 √ forcats 0.5.1#> -- Conflicts ------------------------------------------ tidyverse_conflicts() --
#> x dplyr::filter() masks stats::filter()
#> x dplyr::lag() masks stats::lag()tidyverse 整合 ggplot2, purrr, tibble, dplyr, tidyr, stringr, readr, forcats,海羅了處理資料的基本方法。
今天進一步介紹 dplyr ,還有開始使用 ggplot2。
- 為何寫成
ggplot2::mpg?兩個冒號::是什麼?
告訴大家 mpg 是在 ggplot2 包。同理,dplyr::select() 告訴大家 select() 在 dplyr 包。暫時可以把 :: 當作一種方法,代表取包裡的東西。當然你不能寫成 ggplot2$mpg,因為 $ 是取資料的變數,比如 mpg$cty,是另外一種方法。
- 有推薦其他寫程式的好方法嗎?
有,複製別人寫好的,貼上運行。因為我們要站在巨人的肩膀上。
dplyr 資料轉換 & ggplot2 資料視覺化
資料轉換和資料視覺化的內容很豐富,所以會在未來的課程不斷的加入新的內容,持續堆疊下去。如果有不熟悉的地方,也許可以考慮複習一下先前教過的內容。
dplyr 資料轉換
未來的課程總共會涵蓋下列 dplyr 中的函數:
filter()andselect()group_by()andungroup()summarize()andsummarise()arrange()anddesc()mutate()
回想上一次我們做過的:
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv"))#> # A tibble: 109 x 4
#> manufacturer cty hwy class
#> <chr> <int> <int> <chr>
#> 1 audi 18 29 compact
#> 2 audi 21 29 compact
#> 3 audi 20 31 compact
#> 4 audi 21 30 compact
#> 5 audi 16 26 compact
#> 6 audi 18 26 compact
#> 7 audi 18 27 compact
#> 8 audi 18 26 compact
#> 9 audi 16 25 compact
#> 10 audi 20 28 compact
#> # ... with 99 more rows在挑出這些資料後,我們想比較不同製造商在其中兩種車型的市區油耗的平均值:
分成兩步驟,分類與取平均值。
Step 1: 分類
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv")) %>%
group_by(manufacturer, class)#> # A tibble: 109 x 4
#> # Groups: manufacturer, class [15]
#> manufacturer cty hwy class
#> <chr> <int> <int> <chr>
#> 1 audi 18 29 compact
#> 2 audi 21 29 compact
#> 3 audi 20 31 compact
#> 4 audi 21 30 compact
#> 5 audi 16 26 compact
#> 6 audi 18 26 compact
#> 7 audi 18 27 compact
#> 8 audi 18 26 compact
#> 9 audi 16 25 compact
#> 10 audi 20 28 compact
#> # ... with 99 more rows可以看到 Groups: manufacturer, class [15] 的訊息。
group_by() 是對某個變數的值做分類。比如 group_by(manufacturer, class) 就是對製造商和車型做分類。
仔細觀察資料的話,會發現並不是所有製造商都有這兩種車型被記錄在資料裡。
Step 2: 取平均值
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv")) %>%
group_by(manufacturer, class) %>%
summarise(avg = mean(cty))#> `summarise()` has grouped output by 'manufacturer'. You can override using the `.groups` argument.#> # A tibble: 15 x 3
#> # Groups: manufacturer [12]
#> manufacturer class avg
#> <chr> <chr> <dbl>
#> 1 audi compact 17.9
#> 2 chevrolet suv 12.7
#> 3 dodge suv 11.9
#> 4 ford suv 12.9
#> 5 jeep suv 13.5
#> 6 land rover suv 11.5
#> 7 lincoln suv 11.3
#> 8 mercury suv 13.2
#> 9 nissan compact 20
#> 10 nissan suv 13.8
#> 11 subaru compact 19.8
#> 12 subaru suv 18.8
#> 13 toyota compact 22.2
#> 14 toyota suv 14.4
#> 15 volkswagen compact 20.8summarise() 和 summarize() 功能一樣,純粹是英美式差異。
summarise() 會整合成另一個資料框,avg 是變數名稱,
mean() 是整合的方式,計算 cty 的平均值。
ggplot2 資料視覺化
ggplot(data = mpg) +
geom_point(mapping = aes(x = cty, y = hwy))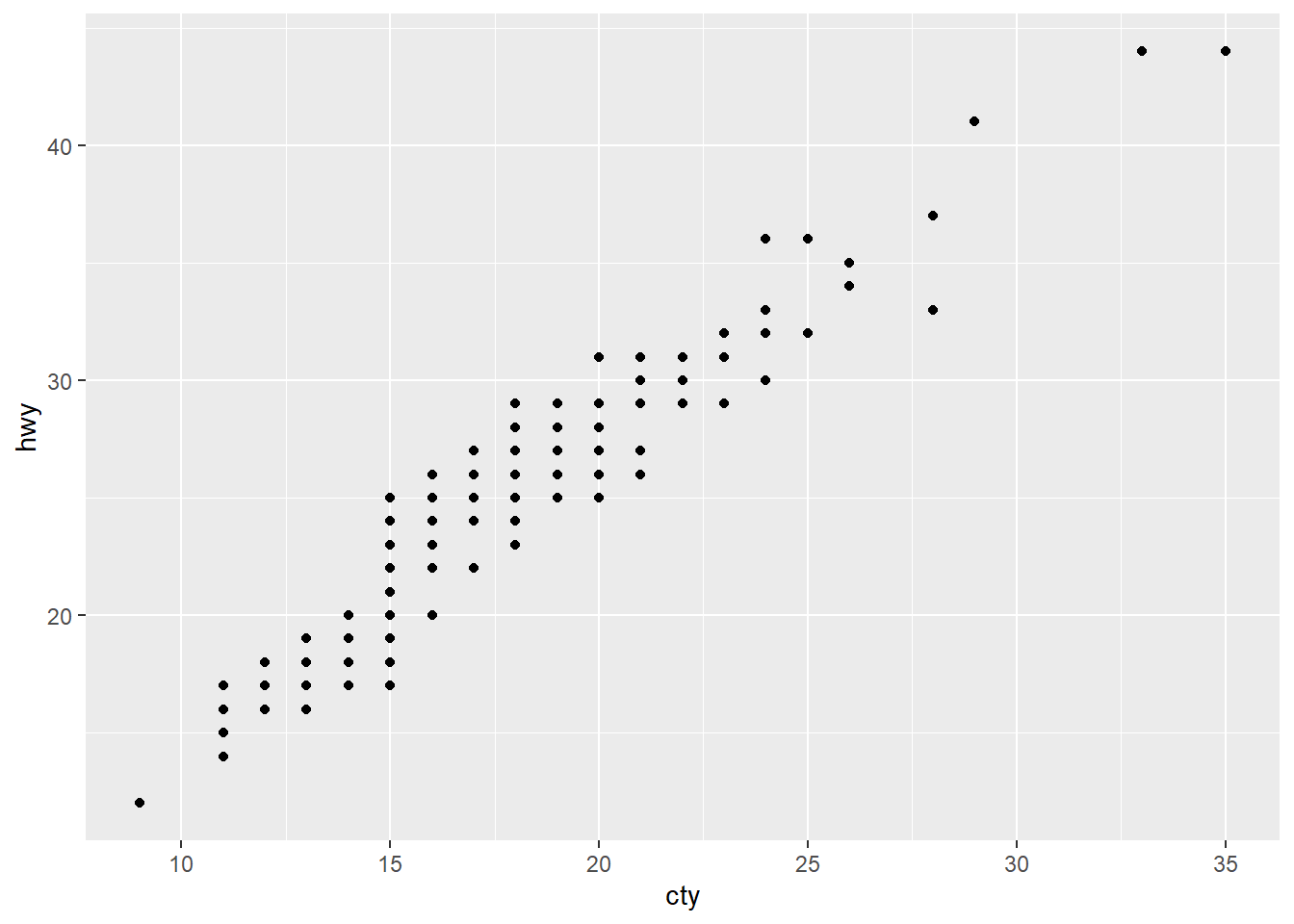
看到 ggplot() 代表要畫圖了,裡面第一個位置放資料 mpg。
這裡的 + 可能跟你想的加法不一樣,
接在 ggplot2 包的函數後面,
就達到跟 %>% 相同的效果。
所以你發現了嗎?這就是個坑,很可能不小心就寫錯。
來看看 RStudio 首席工程師 Hadley 的看法:

ggplot(data = mpg) +
geom_point(mapping = aes(x = cty, y = hwy))geom_point() 是畫點圖。
mapping() 是指映射。
aes() 是 asthetic 的簡稱,是美學的意思。
aes() 放的是座標軸,順序是 x 軸 y 軸。
通常會省略 x、y。
通常會把函數的名稱省略,所以 data、mapping、x、y 都可以省略。但是不能更改他們擺放的順序。所以下面兩個是完全不同的映射方式。
ggplot(mpg) +
geom_point(aes(cty, hwy))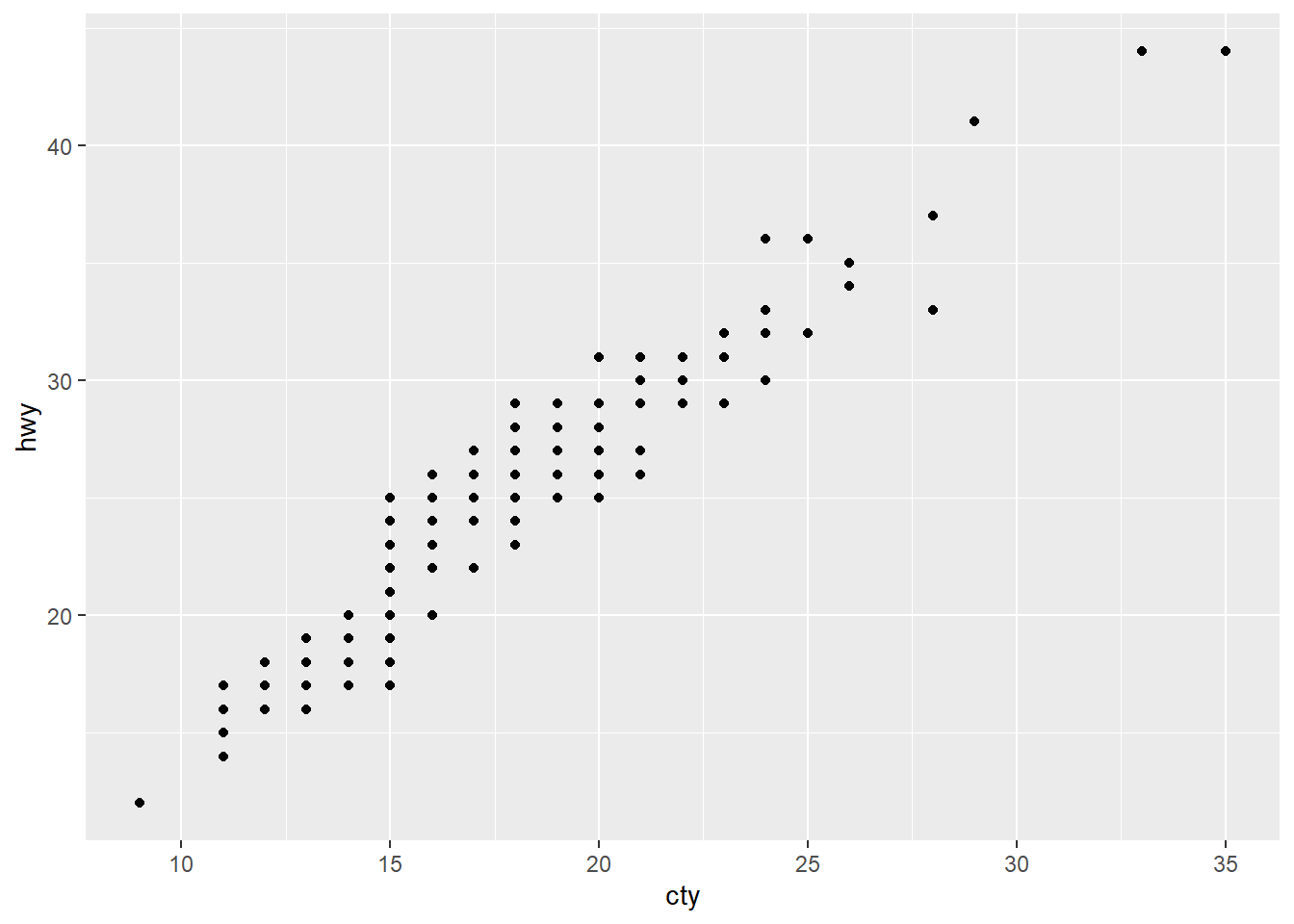
ggplot(mpg) +
geom_point(aes(hwy, cty))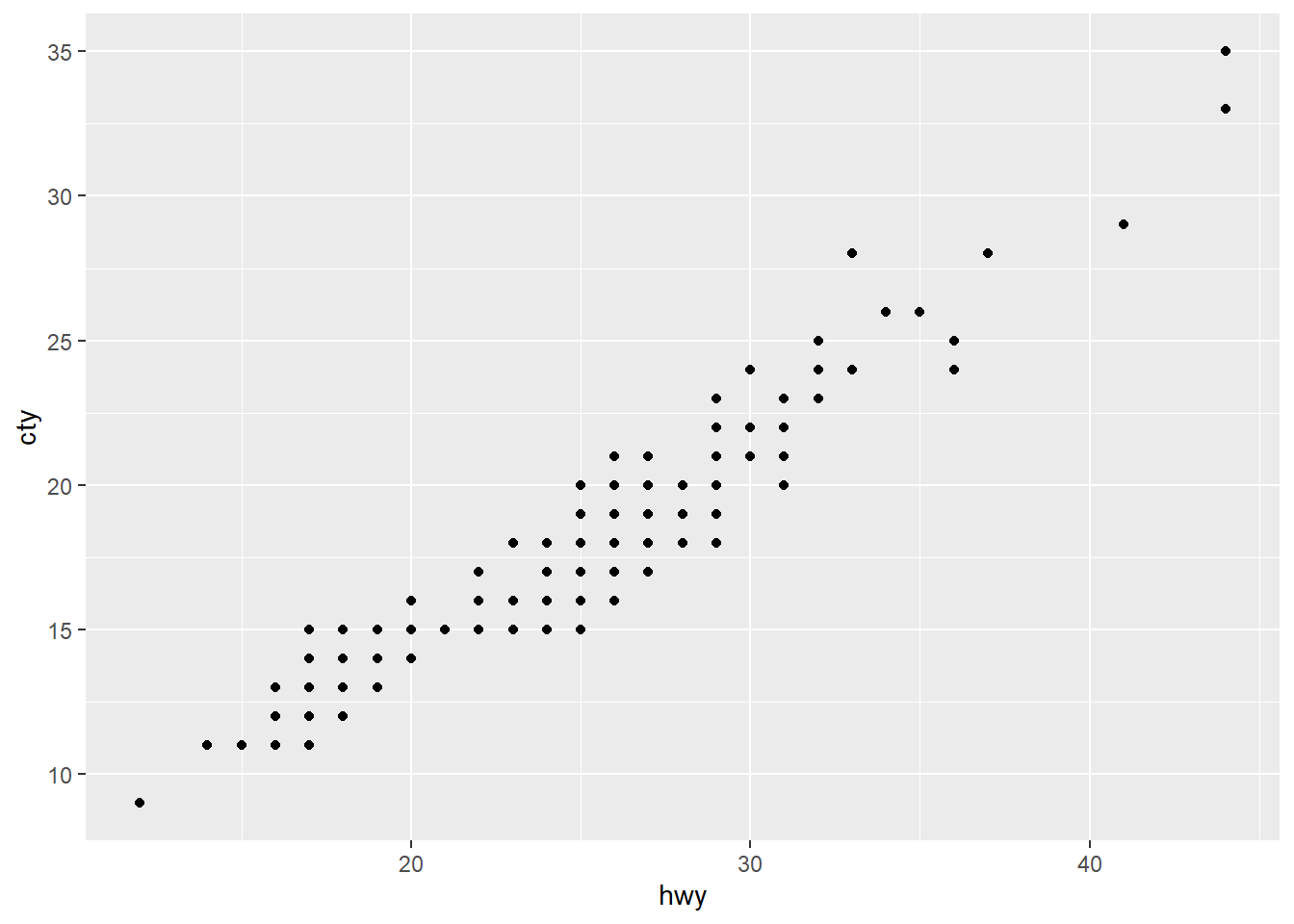
如果要畫兩種以上的圖,只要用 + 連接即可:
ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) +
geom_point() +
geom_smooth(method = lm)#> `geom_smooth()` using formula 'y ~ x'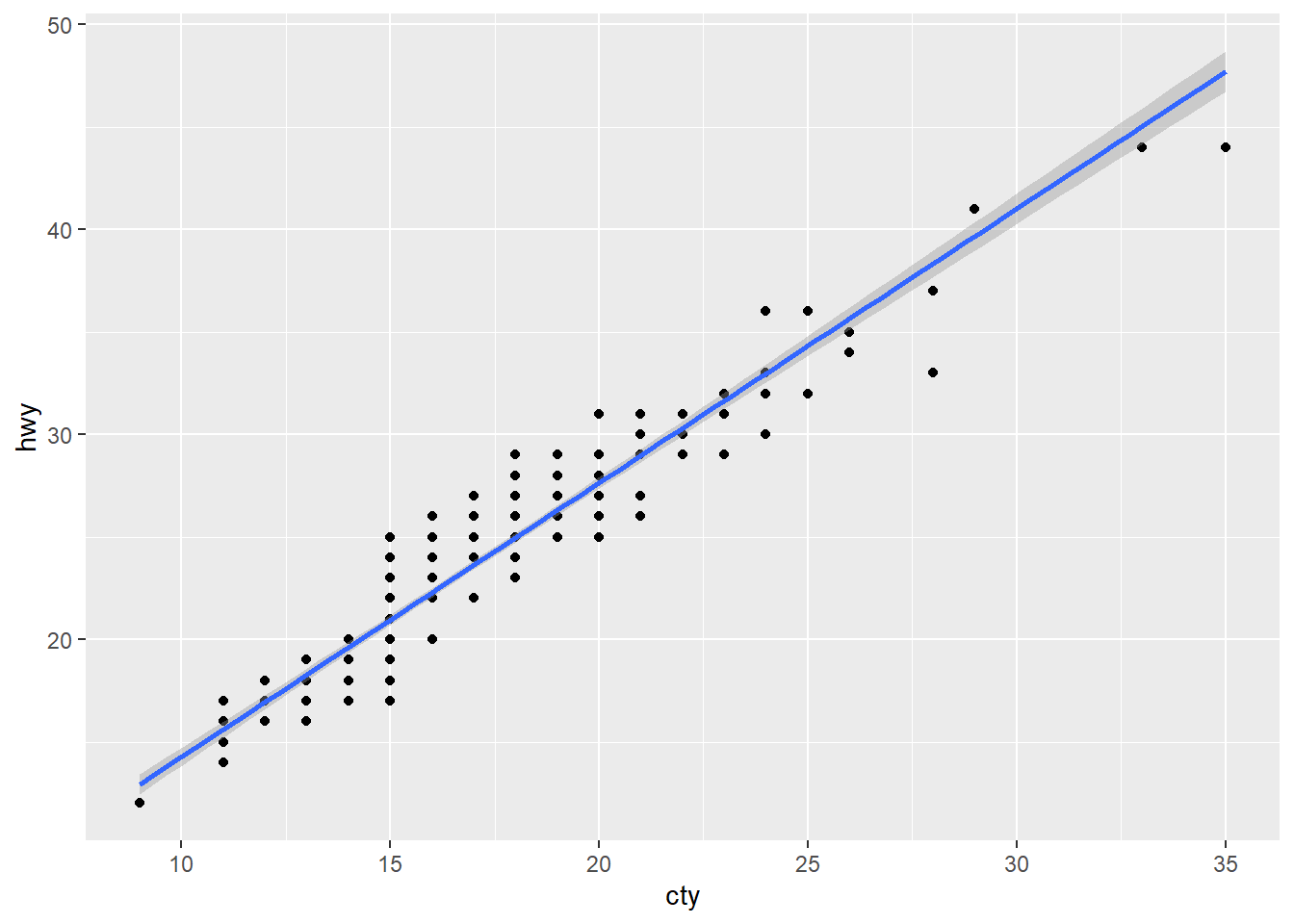
geom_smooth(method = lm) 是指用線性迴歸畫圖,在此不深究這個問題。
作業
1. 請觀察下面兩種做法,分別說明會如何計算總數?
其中 n() 是計算總數,命名為 cars。
解除群組做法是用管線接一句 ungroup(),裡面不用再寫其他記號。
df <- mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv")) %>%
group_by(manufacturer, class)
# 第一種沒有 ungroup
df %>% summarise(cars = n())
# 第二種有 ungroup
df %>%
ungroup() %>%
summarise(cars = n())2. 資料整理的方式如下,
- 接著請畫出製造商在每種車型的市區油耗與高速公路油耗的盒鬚圖。
- 說明
coord_flip()可以解決的問題。 - 說明你喜歡哪一種主題的作圖。比如範例是
theme_classic()畫圖。
提示: geom_boxplot() 的美學在 x 軸是離散的變數,y 軸是連續的變數
當然 color 或是 theme_*() 都可以自行挑選喜歡的。
* 為名稱代換的部分。
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv")) %>%
group_by(manufacturer, class) %>%
ggplot() +
geom_boxplot(mapping = aes(x = ___, y = ___), color = "violet") +
geom_boxplot(mapping = aes(x = ___, y = ___), color = "orange") +
coord_flip() +
theme_classic()