預備
library(tidyverse)dplyr 資料轉換 & ggplot2 資料視覺化
dplyr 資料轉換
回想上一次我們做過的:
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv")) %>%
group_by(manufacturer, class) %>%
summarise(avg = mean(cty))#> `summarise()` has grouped output by 'manufacturer'. You can override using the `.groups` argument.#> # A tibble: 15 x 3
#> # Groups: manufacturer [12]
#> manufacturer class avg
#> <chr> <chr> <dbl>
#> 1 audi compact 17.9
#> 2 chevrolet suv 12.7
#> 3 dodge suv 11.9
#> 4 ford suv 12.9
#> 5 jeep suv 13.5
#> 6 land rover suv 11.5
#> 7 lincoln suv 11.3
#> 8 mercury suv 13.2
#> 9 nissan compact 20
#> 10 nissan suv 13.8
#> 11 subaru compact 19.8
#> 12 subaru suv 18.8
#> 13 toyota compact 22.2
#> 14 toyota suv 14.4
#> 15 volkswagen compact 20.8可是想加入高速公路油耗進行比較,要怎麼辦呢?複製貼上,改 cty 為 hwy 是一種作法,但不是很高明。如果要把製造商的 cty 和 hwy 的平均值整理在一起又要再多一個步驟。
這件事情可以用 summarise() 一次做完:
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv")) %>%
group_by(manufacturer) %>%
summarise(cty_avg = mean(cty), hwy_avg = mean(hwy))#> # A tibble: 12 x 3
#> manufacturer cty_avg hwy_avg
#> * <chr> <dbl> <dbl>
#> 1 audi 17.9 26.9
#> 2 chevrolet 12.7 17.1
#> 3 dodge 11.9 16
#> 4 ford 12.9 17.8
#> 5 jeep 13.5 17.6
#> 6 land rover 11.5 16.5
#> 7 lincoln 11.3 17
#> 8 mercury 13.2 18
#> 9 nissan 15.8 21.3
#> 10 subaru 19.2 25.4
#> 11 toyota 19.1 25.6
#> 12 volkswagen 20.8 28.5可是現在沒辦法直接看出哪個製造商的平均油耗最高最低,我們想要排列資料:
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv")) %>%
group_by(manufacturer) %>%
summarise(cty_avg = mean(cty), hwy_avg = mean(hwy)) %>%
arrange(cty_avg)#> # A tibble: 12 x 3
#> manufacturer cty_avg hwy_avg
#> <chr> <dbl> <dbl>
#> 1 lincoln 11.3 17
#> 2 land rover 11.5 16.5
#> 3 dodge 11.9 16
#> 4 chevrolet 12.7 17.1
#> 5 ford 12.9 17.8
#> 6 mercury 13.2 18
#> 7 jeep 13.5 17.6
#> 8 nissan 15.8 21.3
#> 9 audi 17.9 26.9
#> 10 toyota 19.1 25.6
#> 11 subaru 19.2 25.4
#> 12 volkswagen 20.8 28.5arrange() 由小到大排列 cty_avg 這個變數。
希望油耗表現最好的排在第一位,就用 desc() 包住 cty_avg。
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv")) %>%
group_by(manufacturer) %>%
summarise(cty_avg = mean(cty), hwy_avg = mean(hwy)) %>%
arrange(desc(cty_avg))#> # A tibble: 12 x 3
#> manufacturer cty_avg hwy_avg
#> <chr> <dbl> <dbl>
#> 1 volkswagen 20.8 28.5
#> 2 subaru 19.2 25.4
#> 3 toyota 19.1 25.6
#> 4 audi 17.9 26.9
#> 5 nissan 15.8 21.3
#> 6 jeep 13.5 17.6
#> 7 mercury 13.2 18
#> 8 ford 12.9 17.8
#> 9 chevrolet 12.7 17.1
#> 10 dodge 11.9 16
#> 11 land rover 11.5 16.5
#> 12 lincoln 11.3 17市區油耗的表現都不如高速公路的油耗,可能是因為市區會一直塞車,走走停停,所以油耗表現比較差。但是差距有多少呢?
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv")) %>%
group_by(manufacturer) %>%
summarise(cty_avg = mean(cty), hwy_avg = mean(hwy)) %>%
mutate(difference = hwy_avg - cty_avg)#> # A tibble: 12 x 4
#> manufacturer cty_avg hwy_avg difference
#> * <chr> <dbl> <dbl> <dbl>
#> 1 audi 17.9 26.9 9
#> 2 chevrolet 12.7 17.1 4.44
#> 3 dodge 11.9 16 4.14
#> 4 ford 12.9 17.8 4.89
#> 5 jeep 13.5 17.6 4.12
#> 6 land rover 11.5 16.5 5
#> 7 lincoln 11.3 17 5.67
#> 8 mercury 13.2 18 4.75
#> 9 nissan 15.8 21.3 5.50
#> 10 subaru 19.2 25.4 6.20
#> 11 toyota 19.1 25.6 6.55
#> 12 volkswagen 20.8 28.5 7.71mutate() 新增變數,變數命名為 difference,是計算
hwy_avg 和 cty_avg 的差異,
- 跟你想的應該一樣,代表減法。
ggplot2 資料視覺化
回想上一次我們做過的:
ggplot(data = mpg) +
geom_point(mapping = aes(x = cty, y = hwy))
寫法有其他種類的變形,來比較一下:
mpg %>%
ggplot(aes(cty, hwy)) +
geom_point()
ggplot(mpg, aes(cty, hwy)) +
geom_point()
ggplot(mpg) +
geom_point(aes(cty, hwy))
mpg %>%
ggplot() +
geom_point(aes(cty, hwy))第一種是把資料擺在 ggplot() 外頭,再用 %>% 傳到下一步驟。
第二種是把資料擺在 ggplot() 裡面。
第三種把美學擺在畫圖的方式。
或許你能寫出第四種,再想第五種…
但是,別寫成這樣,是錯的:
ggplot(mpg, cty, hwy) +
geom_point()#> Error in ggplot.default(mpg, cty, hwy): object 'cty' not foundggplot(mpg) +
geom_point(cty, hwy)#> Error in layer(data = data, mapping = mapping, stat = stat, geom = GeomPoint, : object 'cty' not found在回到剛才整理過的資料,現在要以視覺化的方式呈現,我們想看出市區與高速公路油耗的差異:
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class %in% c("compact", "suv")) %>%
group_by(manufacturer) %>%
summarise(cty_avg = mean(cty), hwy_avg = mean(hwy)) %>%
mutate(difference = hwy_avg - cty_avg) %>%
ggplot() +
geom_col(aes(manufacturer, hwy_avg),
alpha = 0.2, fill = "orange", color = "darkorange") +
geom_col(aes(manufacturer, difference),
alpha = 0.3, fill = "violet", color = "purple") +
coord_flip() +
theme_classic()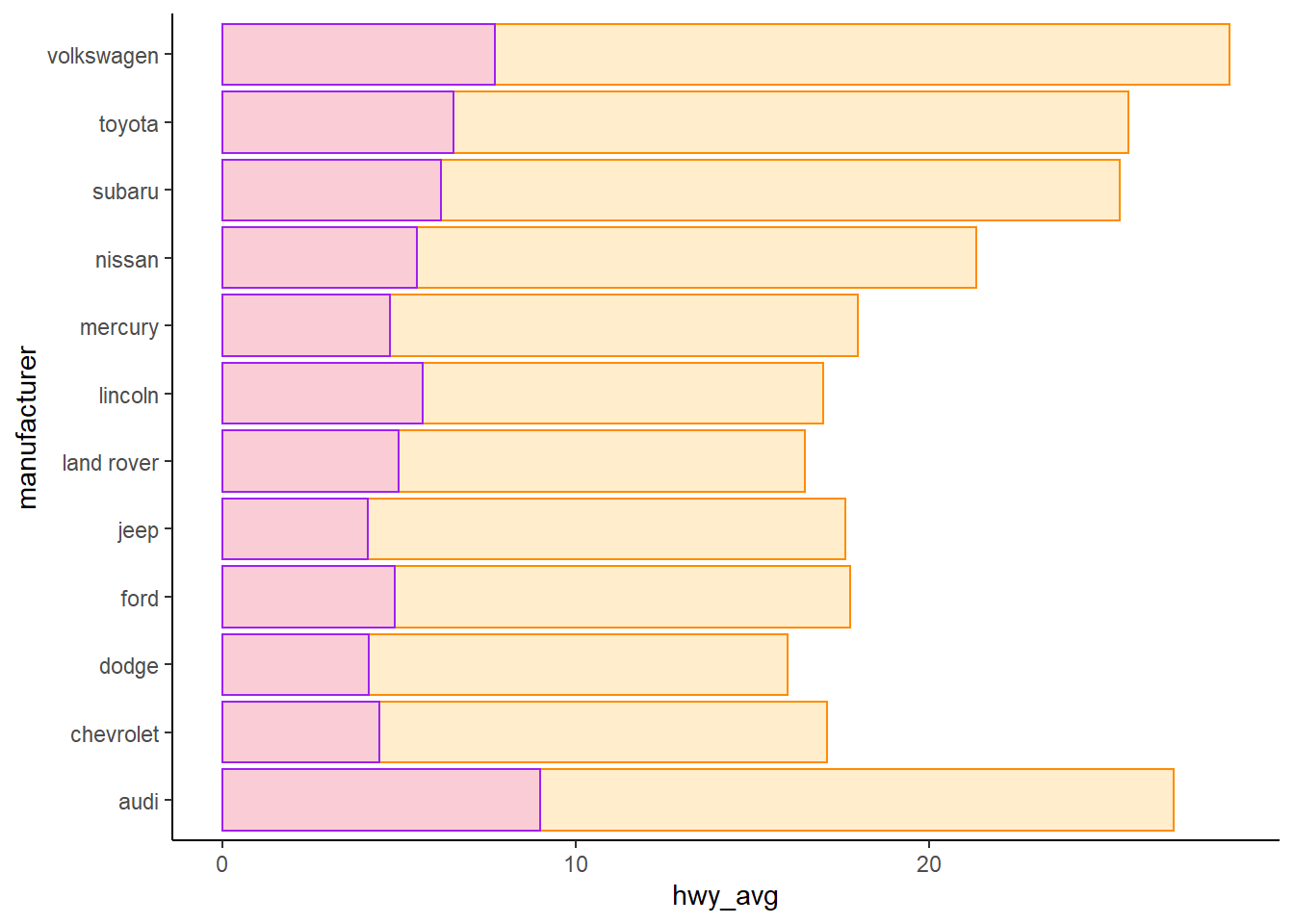
geom_col() 和 geom_boxplot() 都適用於雙變數,一個離散,一個連續。也許你可以試著疊加盒鬚圖與長條圖。
只要用顏色就能區分即可,所以使用 difference 比 cty_avg 更適當。
當然可以自行嘗試使用 cty_avg 的後果。
alpha 設定透明度。
fill 填滿顏色。
color 邊框顏色。