預備
library(tidyverse)tidyr 齊整資料 & ggplot2 資料視覺化
回想上一次我們做過的:
不同製造商的小型車在市區油耗和高速公路油耗的平均值,
mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class == "compact") %>%
group_by(manufacturer) %>%
summarise(cty_avg = mean(cty), hwy_avg = mean(hwy))#> # A tibble: 5 x 3
#> manufacturer cty_avg hwy_avg
#> * <chr> <dbl> <dbl>
#> 1 audi 17.9 26.9
#> 2 nissan 20 28
#> 3 subaru 19.8 26
#> 4 toyota 22.2 30.6
#> 5 volkswagen 20.8 28.5將整理過的資料命名為 df,
df <- mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class == "compact") %>%
group_by(manufacturer) %>%
summarise(cty_avg = mean(cty), hwy_avg = mean(hwy))為了更有效的操作,會將資料的數個變數合併成新變數,在此我們先專注在資料輸出的樣子,還有畫圖的表現,再回頭解釋程式碼,比如:
df#> # A tibble: 5 x 3
#> manufacturer cty_avg hwy_avg
#> * <chr> <dbl> <dbl>
#> 1 audi 17.9 26.9
#> 2 nissan 20 28
#> 3 subaru 19.8 26
#> 4 toyota 22.2 30.6
#> 5 volkswagen 20.8 28.5df %>%
gather(cty_avg, hwy_avg, key = "avg", value = "value")#> # A tibble: 10 x 3
#> manufacturer avg value
#> <chr> <chr> <dbl>
#> 1 audi cty_avg 17.9
#> 2 nissan cty_avg 20
#> 3 subaru cty_avg 19.8
#> 4 toyota cty_avg 22.2
#> 5 volkswagen cty_avg 20.8
#> 6 audi hwy_avg 26.9
#> 7 nissan hwy_avg 28
#> 8 subaru hwy_avg 26
#> 9 toyota hwy_avg 30.6
#> 10 volkswagen hwy_avg 28.5df %>%
gather(cty_avg, hwy_avg, key = "avg", value = "value") %>%
ggplot() +
geom_col(aes(manufacturer, value)) +
facet_wrap(~ avg)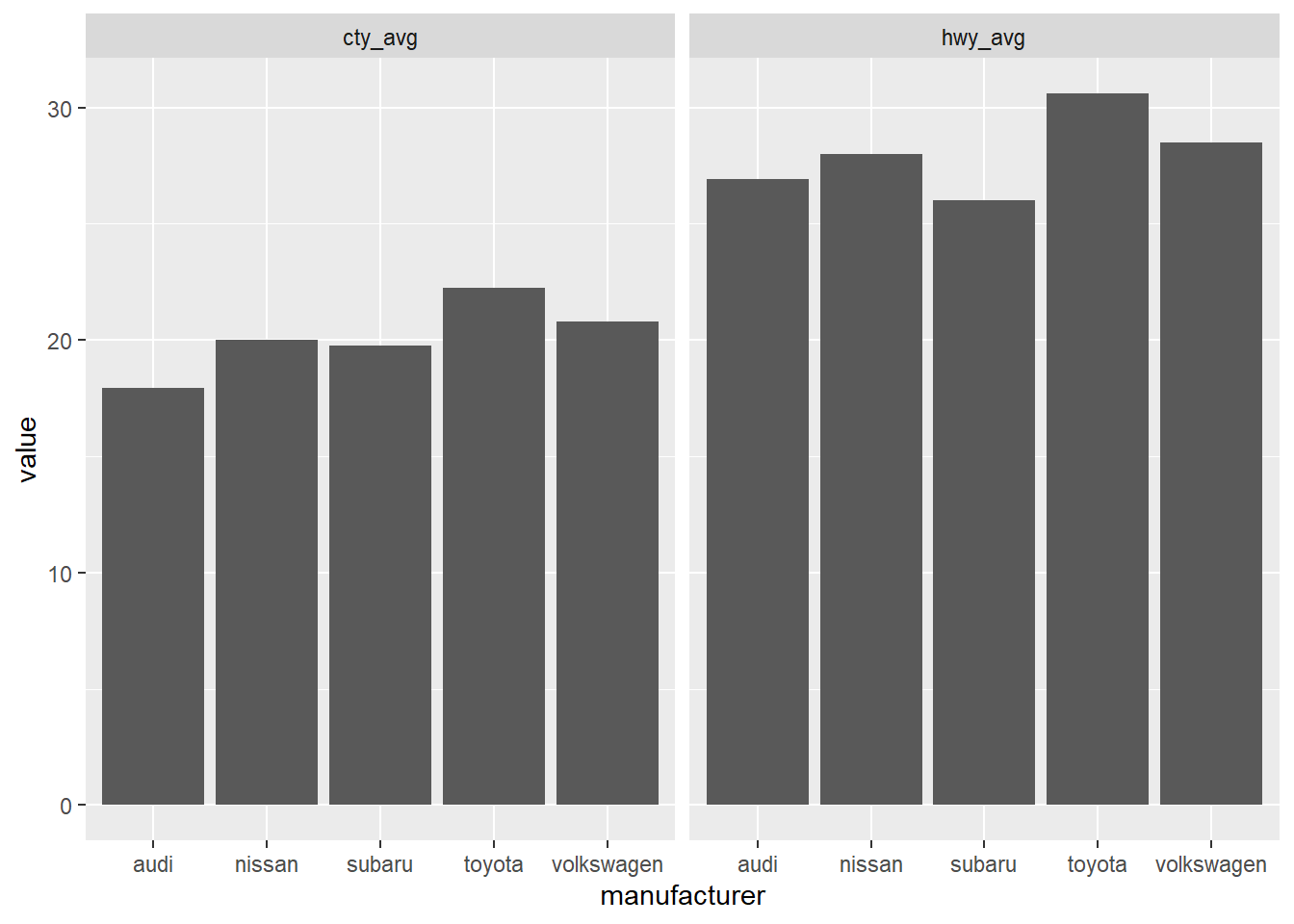
df %>%
gather(cty_avg, hwy_avg, key = "avg", value = "value") %>%
ggplot() +
geom_col(aes(avg, value)) +
facet_wrap(~ manufacturer, nrow = 1)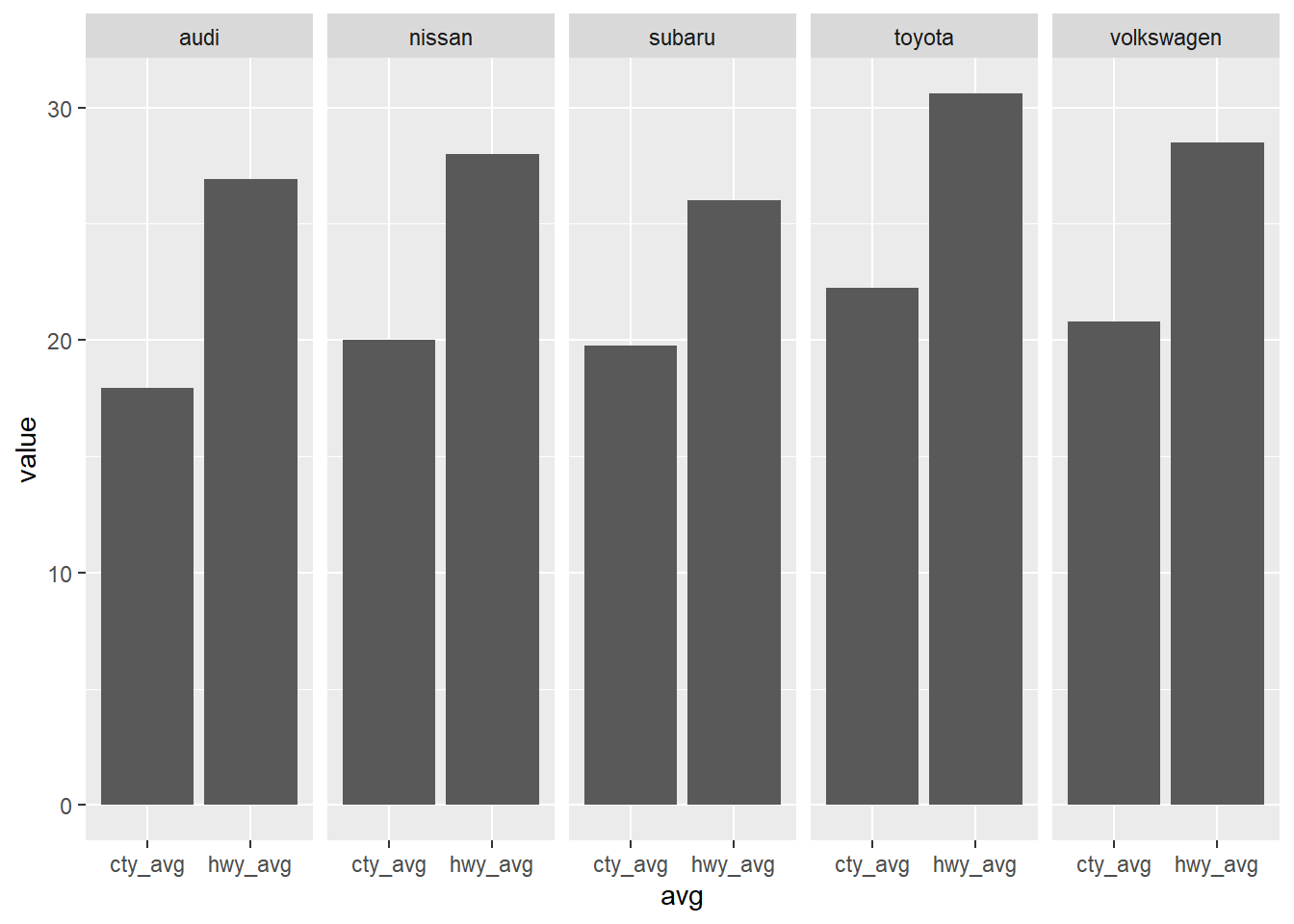
現在開始解釋程式碼。
df#> # A tibble: 5 x 3
#> manufacturer cty_avg hwy_avg
#> * <chr> <dbl> <dbl>
#> 1 audi 17.9 26.9
#> 2 nissan 20 28
#> 3 subaru 19.8 26
#> 4 toyota 22.2 30.6
#> 5 volkswagen 20.8 28.5df %>%
gather(cty_avg, hwy_avg, key = "avg", value = "value")#> # A tibble: 10 x 3
#> manufacturer avg value
#> <chr> <chr> <dbl>
#> 1 audi cty_avg 17.9
#> 2 nissan cty_avg 20
#> 3 subaru cty_avg 19.8
#> 4 toyota cty_avg 22.2
#> 5 volkswagen cty_avg 20.8
#> 6 audi hwy_avg 26.9
#> 7 nissan hwy_avg 28
#> 8 subaru hwy_avg 26
#> 9 toyota hwy_avg 30.6
#> 10 volkswagen hwy_avg 28.5gather 將數個資料變數合併到新的變數,
前面放所有要合併的變數名稱,此為 cty_avg 和 hwy_avg。
key 將新變數命名為 avg。
value 是原有變數的值,值放在另一個命名為 value 的新變數。
df %>%
gather(cty_avg, hwy_avg, key = "avg", value = "value") %>%
ggplot() +
geom_col(aes(manufacturer, value)) +
facet_wrap(~ avg)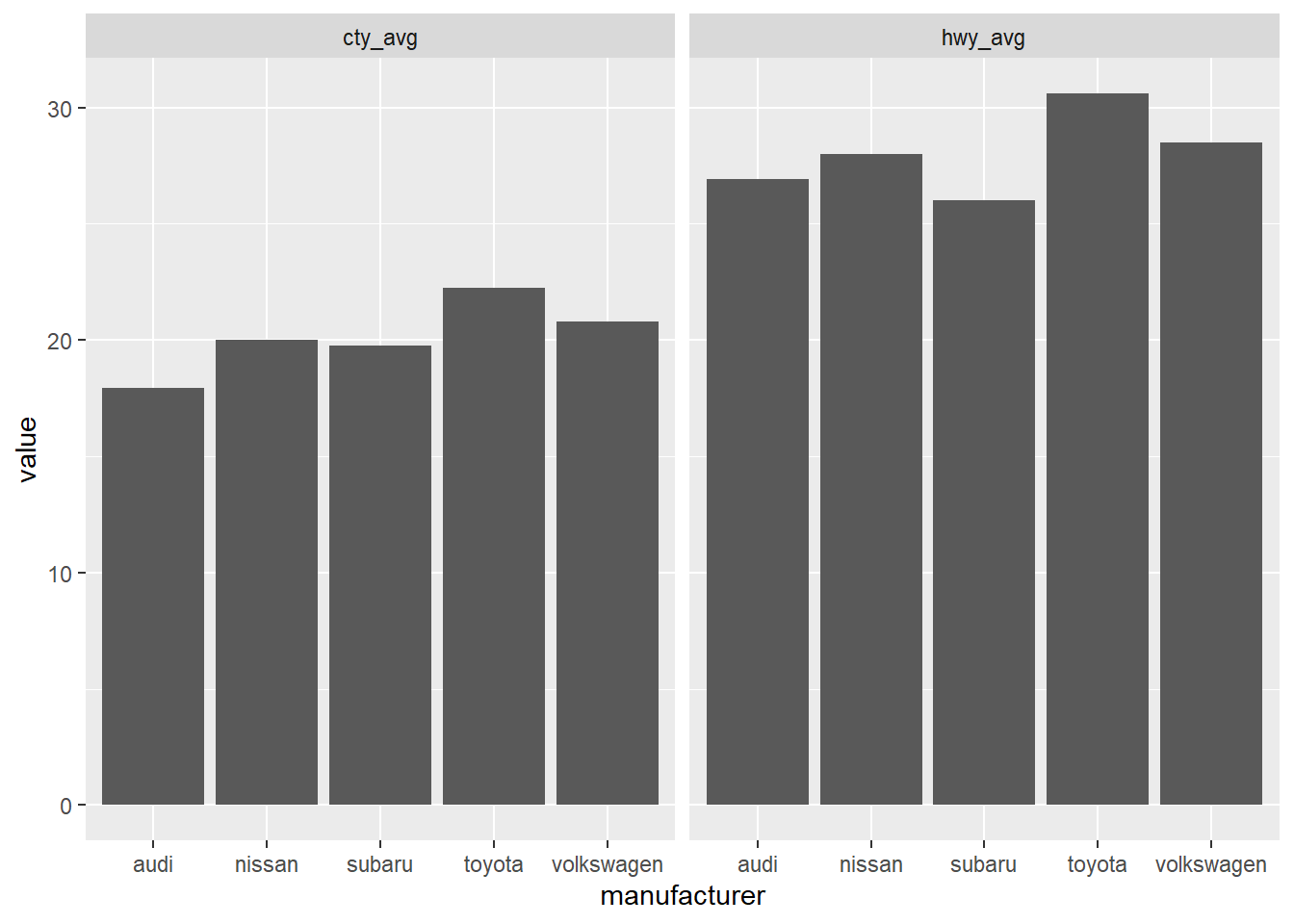
原有資料在合併變數後更易於畫圖,可以避免疊圖的寫法,省去不必要的麻煩。
取代疊圖的方法是 facet_wrap(),facet 譯作面向,
注意,面向只能針對離散的資料處理。
facet_wrap() 裡面的寫法是 ~ 接面向的變數名稱。
df %>%
gather(cty_avg, hwy_avg, key = "avg", value = "value") %>%
ggplot() +
geom_col(aes(avg, value)) +
facet_wrap(~ manufacturer, nrow = 1)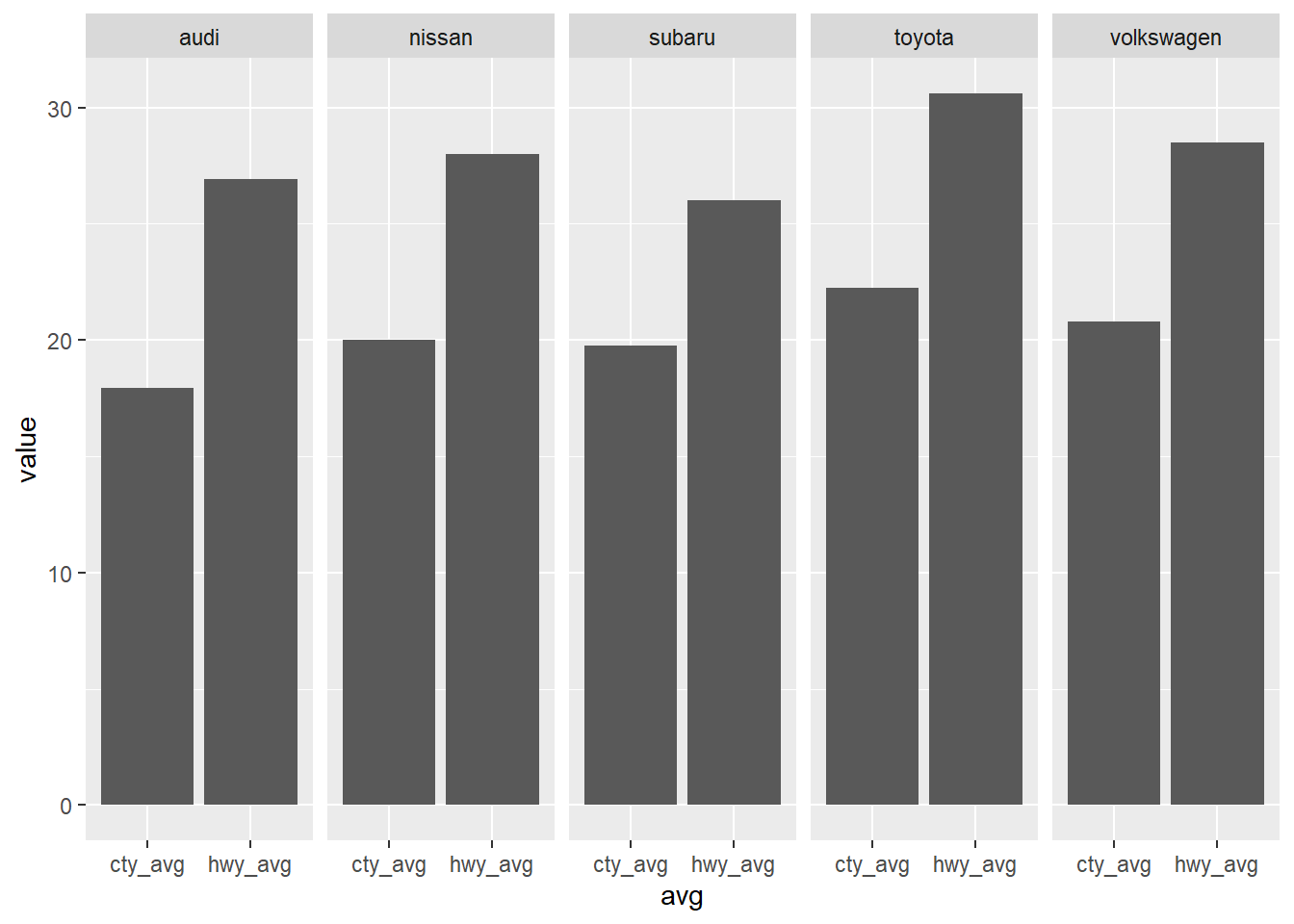
最一開始問的問題是不同製造商的小型車在市區油耗和高速公路油耗的平均值,顯然這時候面向的變數是製造商更為貼切。
每個面向都會產生一張圖,圖片的排列上可以用行列控制。
比如範例設定 nrow = 1,和設定 ncol = 5 相同。
df %>%
gather(cty_avg, hwy_avg, key = "avg", value = "value") %>%
ggplot() +
geom_col(aes(avg, value)) +
facet_wrap(~ manufacturer, nrow = 1) +
coord_flip()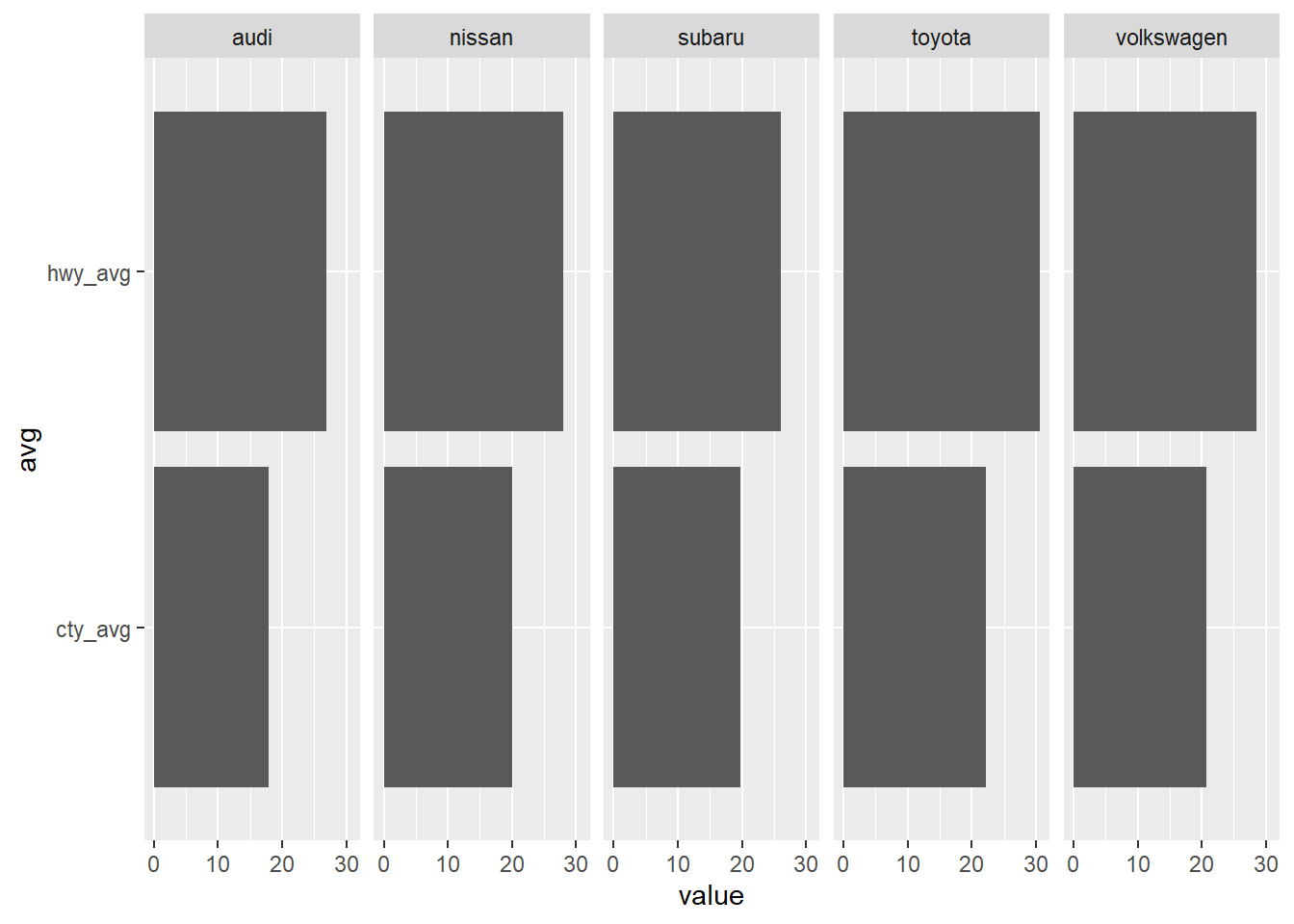
也許你會想加上座標軸的翻轉,但你滿意這個結果嗎?
df %>%
gather(cty_avg, hwy_avg, key = "avg", value = "value") %>%
ggplot() +
geom_col(aes(avg, value)) +
facet_wrap(~ manufacturer, nrow = 5) +
coord_flip()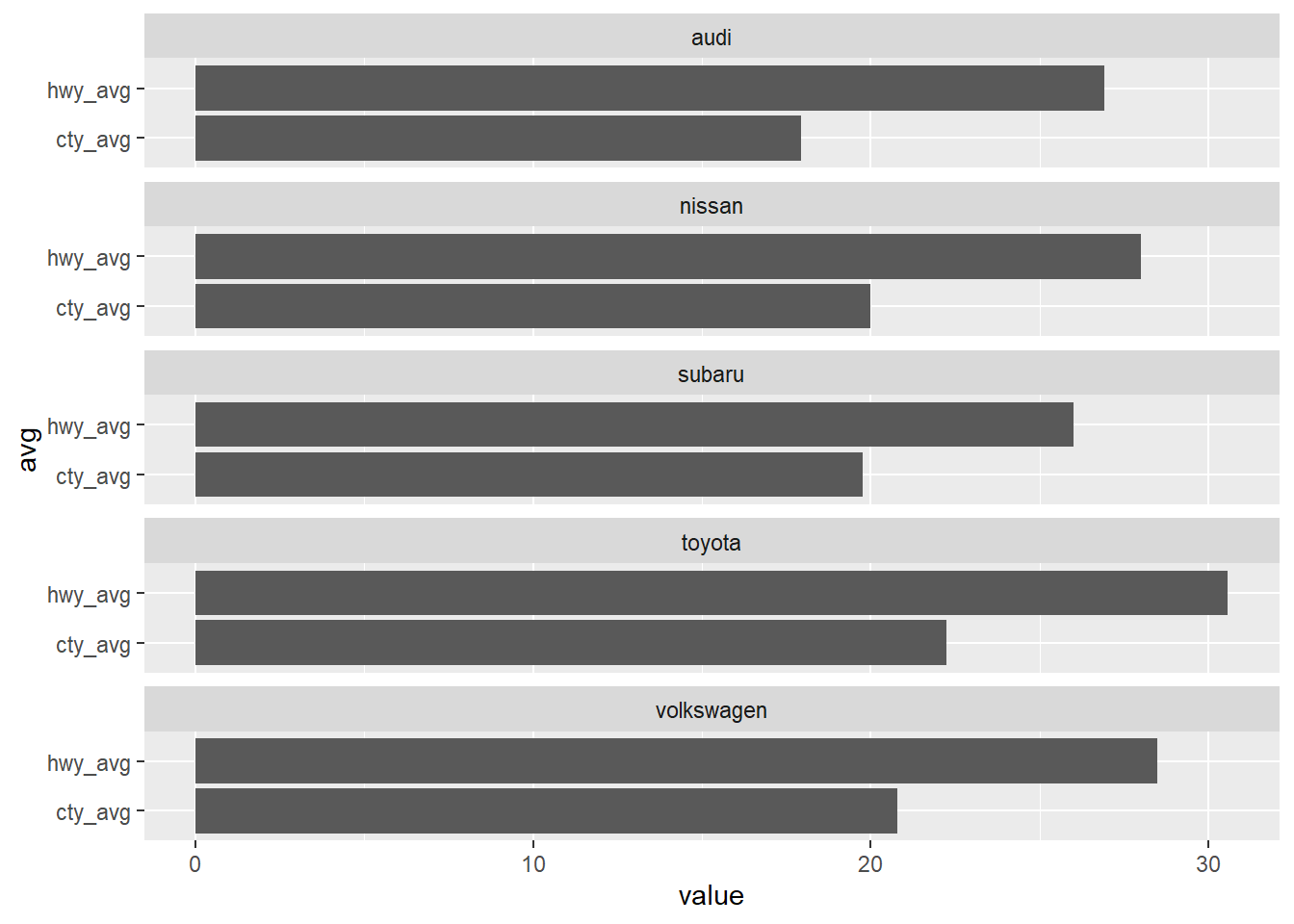
調整行列顯示的圖片數量即可。
作業
此指的 df 程式碼如下:
df <- mpg %>%
select(manufacturer, cty, hwy, class) %>%
filter(class == "compact") %>%
group_by(manufacturer) %>%
summarise(cty_avg = mean(cty), hwy_avg = mean(hwy))1. 資料可以合併變數也可以展開變數。spread() 用於展開變數,
key 接的變數的值,會成為展開的變數名稱。
value 是對應展開變數的值。
df1 <- df %>%
gather(cty_avg, hwy_avg, key = "avg", value = "value")
df2 <- df1 %>%
spread(key = avg, value = value)請問 df2 和 df 是完全相等的嗎?
如果現在寫法改寫如下,df4 會和 df3 完全相等嗎?
df3 <- df %>%
select(cty_avg, hwy_avg, manufacturer)
df4 <- df3 %>%
gather(cty_avg, hwy_avg, key = "avg", value = "value") %>%
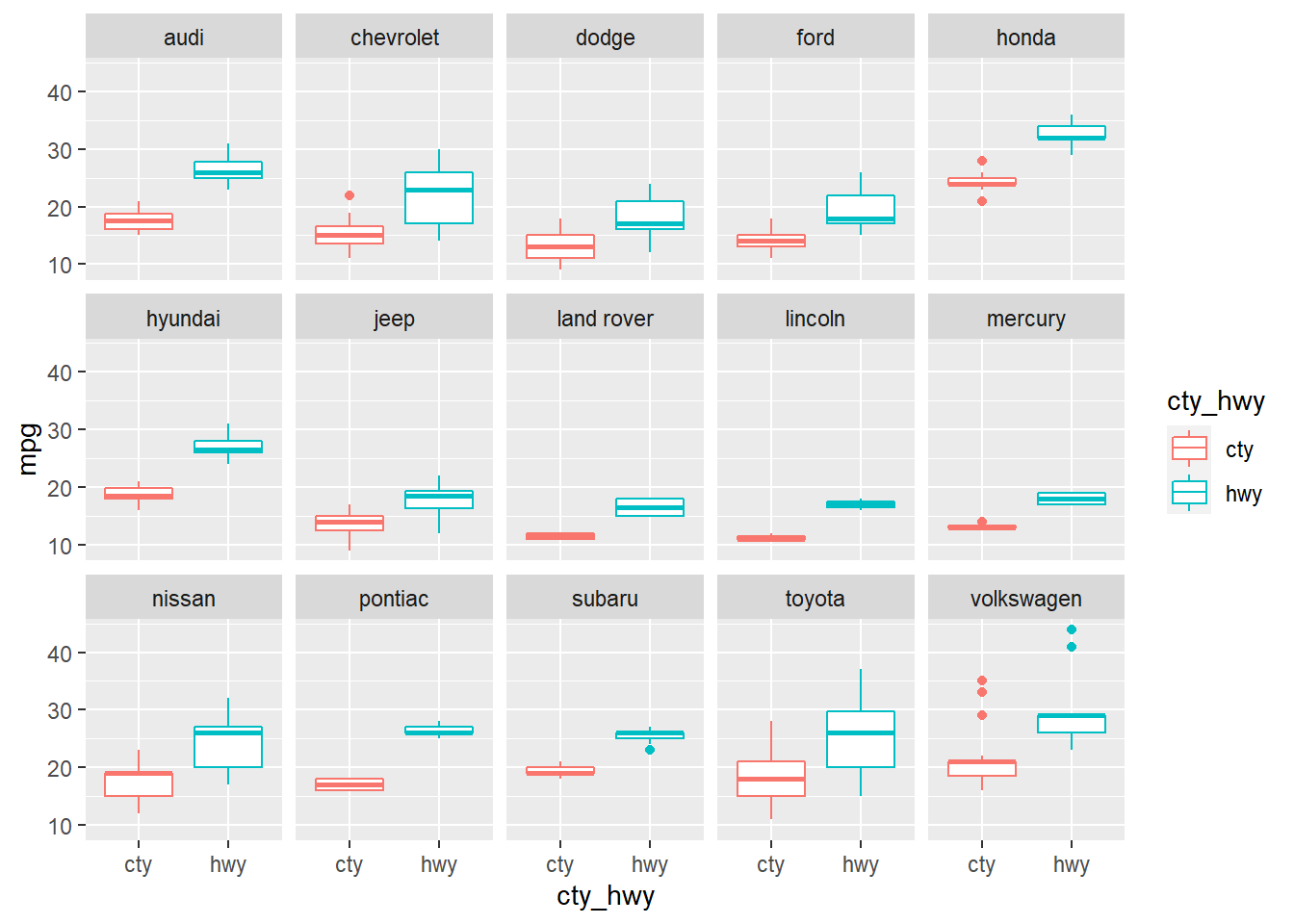
spread(key = avg, value = value)2. 請畫出製造商在每種車型的市區油耗與高速公路油耗的盒鬚圖。使用以下程式碼作答。參考解答如圖。
知道嗎? mpg 表示 miles per gallon,正是 cty 和 hwy 的單位。
mpg %>%
select(manufacturer, cty, hwy, class) %>%
gather(___, ___, key = "cty_hwy", value = ___) %>%
ggplot() +
geom_boxplot(mapping = aes(x = ___, y = ___, color = cty_hwy)) +
facet_wrap(~___, ncol = ___)