預備
library(tidyverse)複習
dplyr 資料轉換
filter()andselect()group_by()andungroup()summarize()andsummarise()arrange()anddesc()mutate()
tidyr 齊整資料
gather()andspread()
ggplot2 資料視覺化
ggplot()geom_point()geom_col()geom_boxplot()facet_wrap()coord_flip()theme_classic()
tibble 資料框
通常 R 的使用者稱資料框都是指 data.frame(),
但資料框 tibble() 在操作上更為方便,因此只介紹 tibble() 的做法。
mpg#> # A tibble: 234 x 11
#> manufacturer model displ year cyl trans drv cty hwy fl class
#> <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
#> 1 audi a4 1.8 1999 4 auto(l~ f 18 29 p comp~
#> 2 audi a4 1.8 1999 4 manual~ f 21 29 p comp~
#> 3 audi a4 2 2008 4 manual~ f 20 31 p comp~
#> 4 audi a4 2 2008 4 auto(a~ f 21 30 p comp~
#> 5 audi a4 2.8 1999 6 auto(l~ f 16 26 p comp~
#> 6 audi a4 2.8 1999 6 manual~ f 18 26 p comp~
#> 7 audi a4 3.1 2008 6 auto(a~ f 18 27 p comp~
#> 8 audi a4 quat~ 1.8 1999 4 manual~ 4 18 26 p comp~
#> 9 audi a4 quat~ 1.8 1999 4 auto(l~ 4 16 25 p comp~
#> 10 audi a4 quat~ 2 2008 4 manual~ 4 20 28 p comp~
#> # ... with 224 more rowsmpg 是 tibble 資料框。
建立資料框:
tibble(x = 1:5, y = x * x)#> # A tibble: 5 x 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 4
#> 3 3 9
#> 4 4 16
#> 5 5 25tibble 允許變數運算成為新變數。
機率模型
df <- tibble(
`隨機抽樣` = rnorm(n = 100, mean = 0, sd = 1),
`機率密度` = dnorm(`隨機抽樣`, mean = 0, sd = 1),
`累積機率` = pnorm(`隨機抽樣`, mean = 0, sd = 1),
`反函數` = qnorm(`累積機率`, mean = 0, sd = 1)
)ggplot(df) +
geom_point(aes(x = `隨機抽樣`, y = `機率密度`))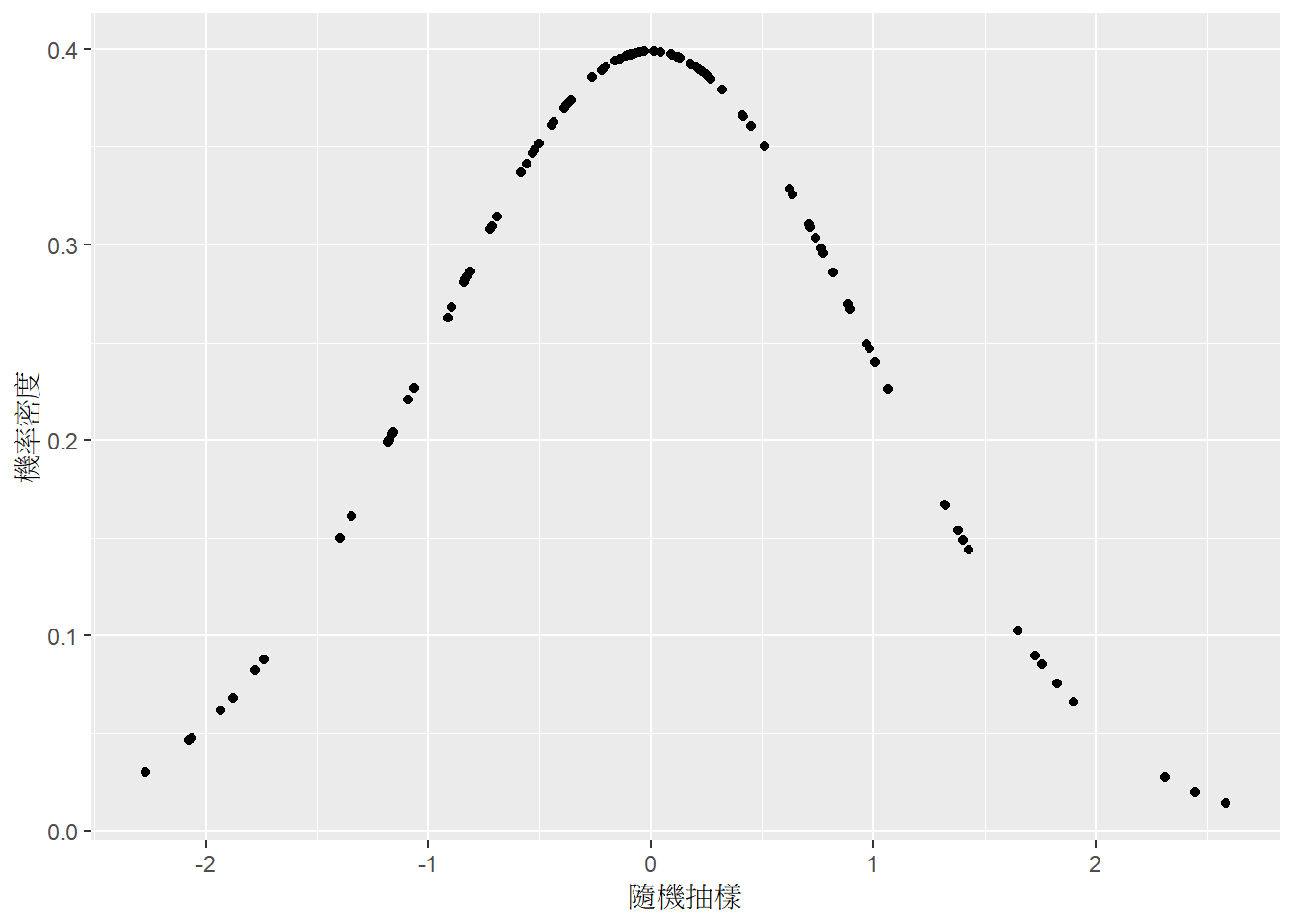
ggplot(df) +
geom_point(aes(x = `隨機抽樣`, y = `累積機率`))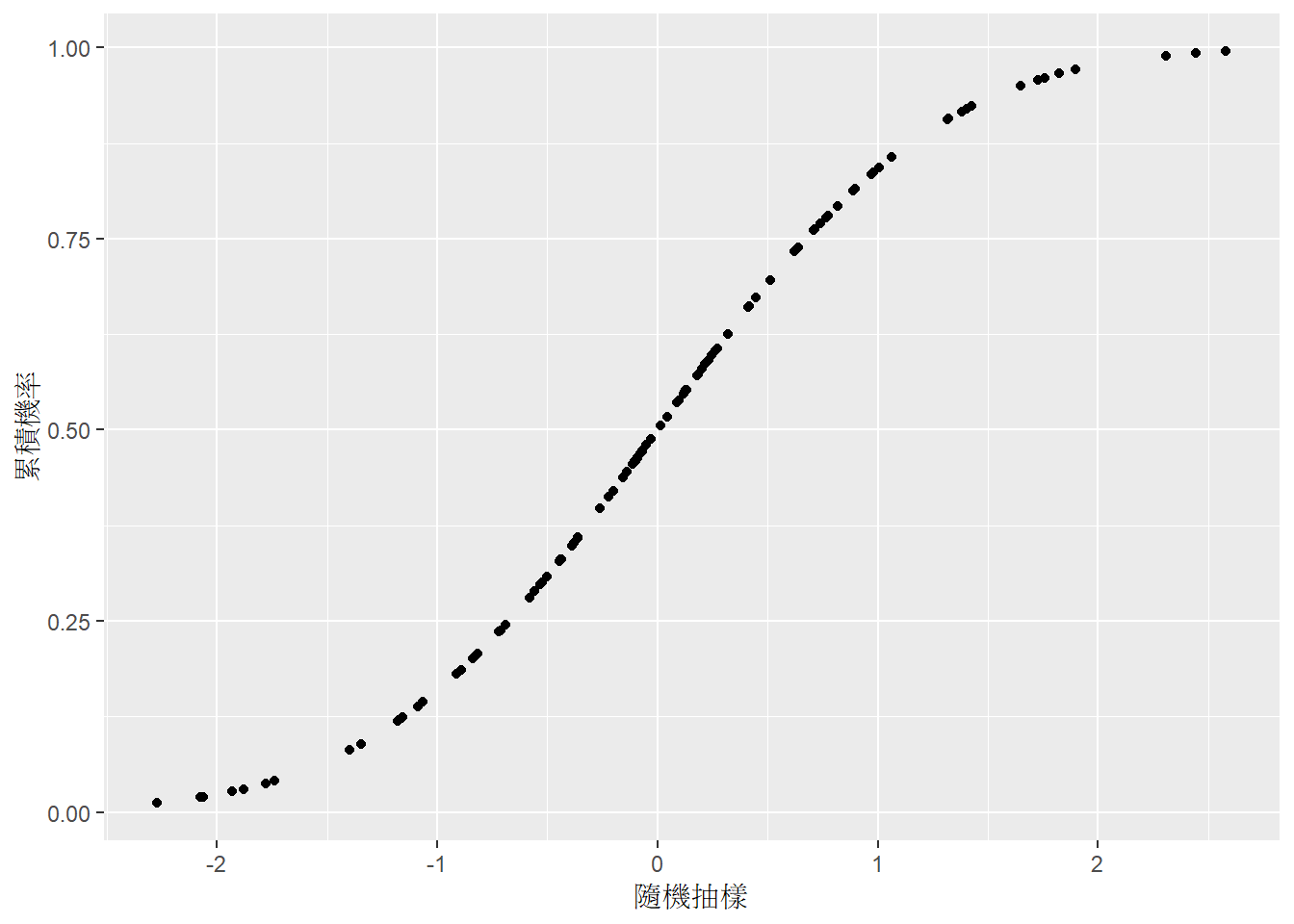
purrr 重複執行
函數
通常需要重複執行的程式碼會寫成函數,比如取常態分配隨機抽樣的函數是 rnorm(),函數中會放入參數名稱與參數值,比如 rnorm(n = 10, mean = 0, sd = 1),屬於完全比對,但是也可以省略參數名稱,簡寫成 rnorm(10, 0, 1),比對的順序會由前往後,為順序比對。
另外,參數名稱也容許部份比對,所以寫成 rnorm(n = 10, m = 0, s = 1) 也可以。參數名稱比對的邏輯是是完全比對,再部分比對,最後是由前往後的順序比對。
rnorm(n = 10, mean = 0, sd = 1)#> [1] -0.3329234 1.3631137 -0.4691473 0.8428756 -1.4579937 -0.4003059
#> [7] -0.7764173 -0.3692965 1.2401015 -0.1074338rnorm(10, 0, 1)#> [1] 0.1725935 0.2546013 -0.6145338 -1.4292151 -0.3309754 0.1283861
#> [7] 1.0181200 -0.2555737 -0.3025410 1.6151907rnorm(n = 10, m = 0, s = 1)#> [1] -0.7737134 0.4240024 -0.5839470 0.4150357 -1.5452617 -0.5187495
#> [7] -0.2797916 1.0074574 -0.4695700 0.2978970自行定義函數與呼叫函數
hello <- function(x = "hello world"){
print(x)
}
hello#> function(x = "hello world"){
#> print(x)
#> }hello()#> [1] "hello world"hello("hi")#> [1] "hi"定義函數 hello(),參數名稱 x,參數值預設為 "hello world",當然也可以不預設參數值。大括號寫函數執行的事情。
運行 hello 會看到函數的程式碼。運行 hello() 會以預設值執行函數,運行 hello("hi") 會以設定值執行函數。
有了這些知識後,接著討論如何應用在 purrr 的函數。
purrr::map()
# 1
func <- function(number) number ** 2
map(1:5, func)
# 2
map(1:5, function(number) number ** 2)
# 3
map(1:5, ~ .x ** 2)
# 4
map(1:5, ~ . ** 2)
# 注意
map# 1
func <- function(number) number ** 2
map(1:5, func)#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 4
#>
#> [[3]]
#> [1] 9
#>
#> [[4]]
#> [1] 16
#>
#> [[5]]
#> [1] 25# 2
map(1:5, function(number) number ** 2)#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 4
#>
#> [[3]]
#> [1] 9
#>
#> [[4]]
#> [1] 16
#>
#> [[5]]
#> [1] 25# 3
map(1:5, ~ .x ** 2)#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 4
#>
#> [[3]]
#> [1] 9
#>
#> [[4]]
#> [1] 16
#>
#> [[5]]
#> [1] 25# 4
map(1:5, ~ . ** 2)#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 4
#>
#> [[3]]
#> [1] 9
#>
#> [[4]]
#> [1] 16
#>
#> [[5]]
#> [1] 25# 注意
map#> function (.x, .f, ...)
#> {
#> .f <- as_mapper(.f, ...)
#> .Call(map_impl, environment(), ".x", ".f", "list")
#> }
#> <bytecode: 0x0000000014179000>
#> <environment: namespace:purrr>map() 的第一個參數值放的是 list 或是 vector,第二個參數值放的是函數。
map() 會將第一個參數值逐一傳給第二個函數執行。
在第一種寫法, func() 會計算參數值的平方,
因此 map(1:5, func) 會計算出 1 到 5 的平方。
第二種寫法減少為函數取名的麻煩,而第三種寫法是精簡第二種的寫法,
注意 .x 是配合 map 第一個參數名稱的寫法,又因為容許部分比對,所以可以寫成第四種。
再看另一個 map() 的應用範例。
random_sample <- function() {
rnorm(2, 0, 1)
}
random_sample()
# error
map(1:10, random_sample)
map(1:10, function() rnorm(2, 0, 1))函數並不需要參數名稱,所以在 function() 的 () 中不需要寫任何東西,函數也能成功執行,但是應用到 map() 函數的時候就會出問題。
造成這個問題的原因是函數比對不成功,為了解決這個問題,可以取一個不會被函數的程式碼使用的參數名稱。比如:
map(1:10, function(x) rnorm(2, 0, 1))#> [[1]]
#> [1] -0.4177944 -0.8503808
#>
#> [[2]]
#> [1] 0.6890462 -0.4601962
#>
#> [[3]]
#> [1] 1.3481844 0.4430714
#>
#> [[4]]
#> [1] -0.1509262 0.4555489
#>
#> [[5]]
#> [1] -0.04015468 0.45612104
#>
#> [[6]]
#> [1] -0.408425 -2.136494
#>
#> [[7]]
#> [1] 0.1568219 0.6600489
#>
#> [[8]]
#> [1] -0.9818344 -1.1136437
#>
#> [[9]]
#> [1] -0.4373477 -0.5161112
#>
#> [[10]]
#> [1] 0.4189960 0.1341554或是用 ... 即可,... 的意義在於傳遞未使用的參數名稱到下一個函數做使用。
random_sample <- function(...) {
rnorm(2, 0, 1)
}
random_sample()
# correct
map(1:10, random_sample)
map(1:10, function(...) rnorm(2, 0, 1))
map(1:10, ~ rnorm(2, 0, 1))... 傳遞未使用的參數名稱到下一個函數。
g <- function(n, ...){
rnorm(n, ...)
}
g(n = 10, mean = 0, sd = 1)#> [1] 1.03468645 1.65350323 -0.01794682 -0.02420332 0.25024690 -0.33712454
#> [7] -0.11335370 -0.09888291 0.26408682 0.13898369g(n = 10, 50, 1)#> [1] 49.75773 50.05903 49.82273 50.79468 50.00674 49.37021 49.74751 49.30958
#> [9] 50.20254 50.84638g(n = 10, mean = 100, sd = 3)#> [1] 101.89622 100.60424 99.72679 100.86845 99.83595 93.87445 101.07511
#> [8] 98.88220 103.80493 106.50580g(n = 10, sd = 3, mean = 100)#> [1] 96.28083 101.76962 100.37206 98.42888 101.86068 102.12466 99.72040
#> [8] 99.11441 96.74255 98.12555作業
為了檢視同學對於前半學期的內容是否能融會貫通,這次作業請自行挑選資料進行分析,分析的內容至少包含一個題目,並具備完整的文字敘述,以及圖表輔助說明。
可以從 data(package = "ggplot2") 挑選資料,或是其他 package 的資料也可以,
如果同學手邊有自己感興趣的資料,也可以拿來分析。
繳交作業時請註明使用的資料以及附上程式碼。會以程式碼做為評分標準。
文字內容: 5分 表: 5分 圖: 5分