單組樣本的假設檢定
雙尾
\[ \begin{aligned} \left\{ \begin{array}{ll} H_0: & \theta = \theta_0\\ H_1: & \theta \neq \theta_0 \end{array} \right. \end{aligned} \]
\[ \begin{aligned} \left\{ \begin{array}{ll} H_0: & \theta = \theta_0\\ H_1: & \theta = \theta_1 \end{array} \right. \end{aligned} \]
單尾
左尾
\[ \begin{aligned} \left\{ \begin{array}{ll} H_0: & \theta = \theta_0\\ H_1: & \theta < \theta_0 \end{array} \right. \end{aligned} \]
\[ \begin{aligned} \left\{ \begin{array}{ll} H_0: & \theta \geq \theta_0\\ H_1: & \theta < \theta_0 \end{array} \right. \end{aligned} \]
右尾
\[ \begin{aligned} \left\{ \begin{array}{ll} H_0: & \theta = \theta_0\\ H_1: & \theta > \theta_0 \end{array} \right. \end{aligned} \]
\[ \begin{aligned} \left\{ \begin{array}{ll} H_0: & \theta \leq \theta_0\\ H_1: & \theta > \theta_0 \end{array} \right. \end{aligned} \]
概念
假設檢定是對未知的參數做檢定,如果樣本得到的參數離假設太遠則拒絕我們的假設。我們並不知道母體真實的參數為何,所以是在觀察到樣本後,才決定檢定過程。因為假設檢定是屬於二元分類,所以虛無假設和對立假設兩者是互斥(disjoint)的。因此我們可以想像樣本空間被分成拒絕和不拒絕兩個區塊,拒絕的區塊被稱為拒絕域(critical region)。同理,參數空間也被分成拒絕和不拒絕兩個區塊。 當我們指定拒絕域,就決定了檢定過程(test procedure)。而我們常以統計量來表示拒絕域(rejection region)。也就是所謂檢定統計量屬於拒絕域的時候拒絕虛無假設。
我們把拒絕虛無假設的機率以檢定力函數(power function)表示, 意思是在檢定過程下,參數會拒絕虛無假設的機率。 也代表在這個參數下,樣本屬於檢定過程的拒絕域的機率。 理想的情況下,檢定力函數會是\(0\)或\(1\)。也就是虛無假設為真的時候,拒絕虛無假設的機率為\(0\);而虛無假設為假的時候,拒絕虛無假設的機率為\(1\)。 但是在實務上,我們只能希望錯誤的拒絕越小越好,而正確的拒絕越大越好。然而當型一誤差變小的時候,型二誤差變大;當型一誤差變大的時候,型二誤差變小。
\[ \begin{aligned} \left\{ \begin{array}{ll} H_0: & \mu = 0\\ H_1: & \mu = 2 \end{array} \right. \end{aligned} \]
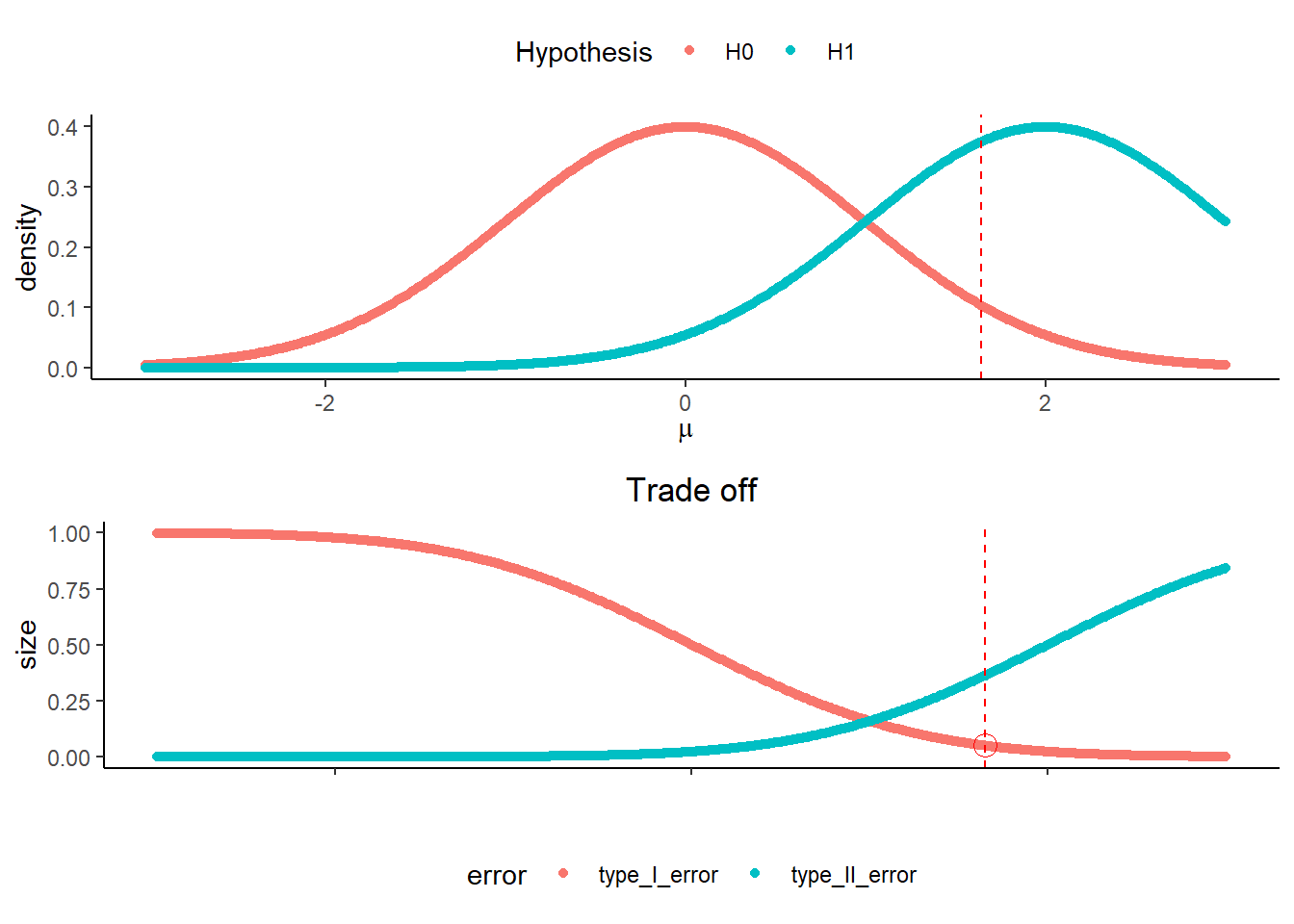
上面的兩張圖,是以\(0.05\)的顯著水準為例,說明在不同的臨界值,型一誤差與型二誤差的權衡。
上方的圖表示在不同參數下所對應的檢定統計量的機率分布,紅色實線表示虛無假設的參數所對應的檢定統計量的機率分布,藍色實線表示對立假設的參數所對應的檢定統計量的機率分布。紅色虛線表示臨界值。下方的圖表示在這個臨界值之下的型一誤差與型二誤差。當我們選定不同的臨界值,型一誤差與型二誤差也會隨之變動,是所謂型一誤差與型二誤差的權衡。
接著舉例說明檢定力函數。再次以右尾檢定為例。\(30\)個樣本,檢定母體平均數是否小於\(100\),其中母體變異數已知為\(9\)。
\[ \begin{aligned} \left\{ \begin{array}{ll} H_0: & \mu \leq 100\\ H_1: & \mu > 100 \end{array} \right. \end{aligned} \]
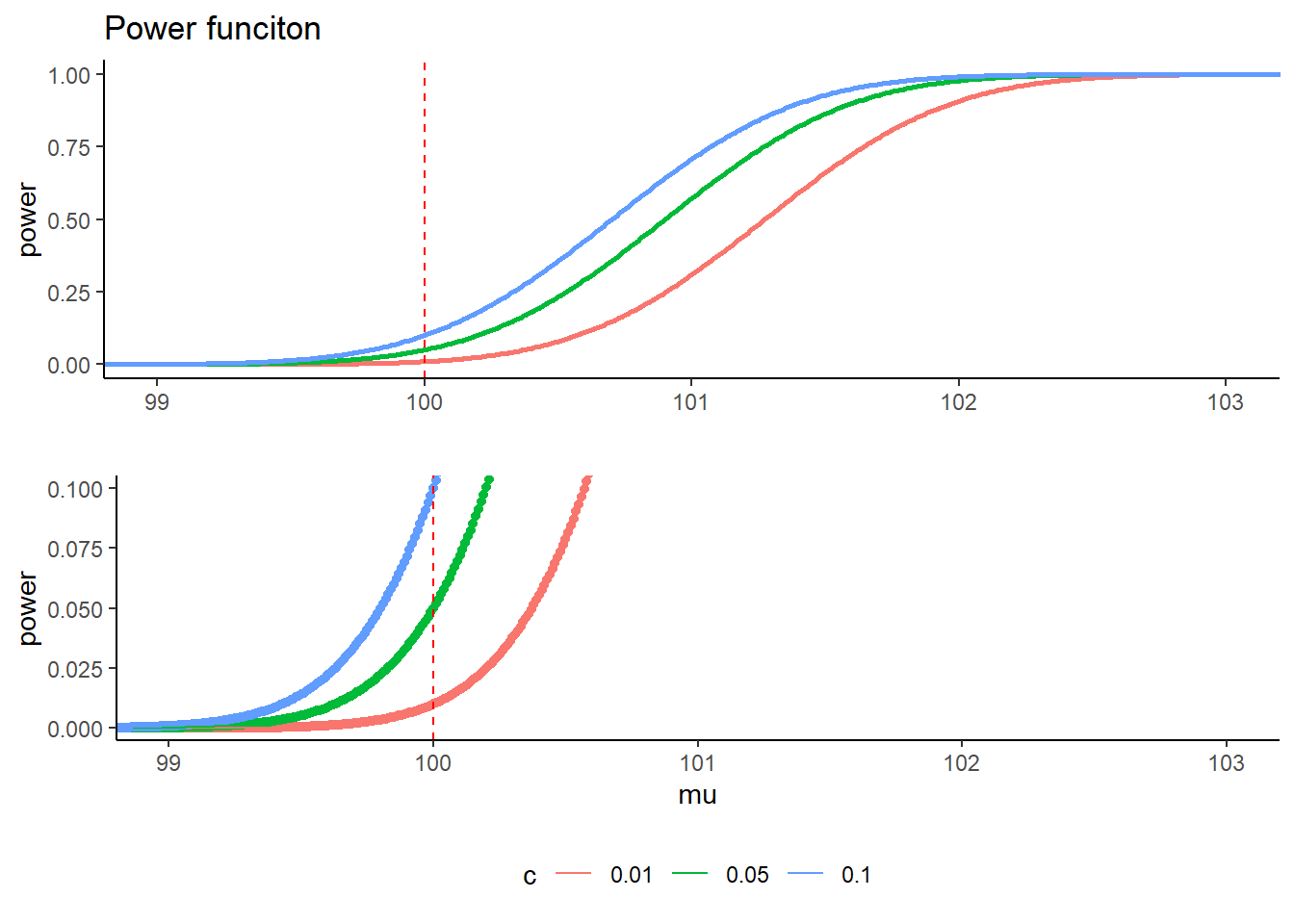
上圖表示在不同顯著水準之下的檢定力函數。紅色虛線表示\(\mu=100\)。雖然無法知道母體平均數為何,但可以了解不同的母體平均數所對應的型一誤差與型二誤差。
接著我們來談 p-value。舉例來說,雙尾檢定常態分配的平均值,變異數已知的情況下,我們在顯著水準\(0.05\)時,拒絕虛無假設,也就是檢定統計量大於\(1.96\)時,回報在顯著水準\(0.05\)時拒絕虛無假設。這樣一來,即使是不相等的檢定統計量,也會得到相同的回報,這樣的回報並沒有太大的效用。如果另外一個研究員想用不同的顯著水準來了解是否拒絕某個檢定統計量,該如何處理?
因此我們在實驗開始前不選定顯著水準,只想了解在哪個顯著水準之下會拒絕虛無假設。從實驗得到統計量,統計量換算出的顯著水準稱為 p-value, 可以解釋為在實驗進行後,p-value 是會拒絕虛無假設的最小顯著水準。 換句話說,比 p-value 小的顯著水準都不會拒絕虛無假設。 所以當 p-value 小於顯著水準時,拒絕虛無假設。比如統計量\(2.66\)得到的 p-value 是\(0.0078\),在顯著水準為\(0.01\)之下,拒絕虛無假設。我們將回報的方式改成統計量\(2.66\),在顯著水準\(0.0078\)顯著。這樣一來,便可知道任何大於\(0.0078\)的顯著水準會拒絕虛無假設,任何小於\(0.0078\)的顯著水準不拒絕虛無假設。
舉例
以左尾檢定為例,假設母體是常態分配,在母體標準差已知為\(25\)的情況下,對母體平均數做檢定。
首先建立虛無假設與對立假設。
\[ \begin{aligned} \left\{ \begin{array}{ll} H_0: & \mu \geq 200\\ H_1: & \mu < 200 \end{array} \right. \end{aligned} \]
我們能控制的是型一誤差,也就是課本所說的顯著水準,選 \(\alpha = 0.05\)。
以左尾檢定來說,檢定統計量小於臨界值的時候,檢定統計量屬於拒絕域。
第一種: 由檢定統計量判斷
當然我們可以由檢定統計量來決定拒絕域,此時臨界值的計算方式如下,
critical.value <- qnorm(0.05, mean = 0, sd = 1)
critical.value#> [1] -1.644854由於母體標準差已知,檢定統計量為\(Z\)。
\[ \begin{aligned} Z = \frac{\bar X - \mu}{\frac{\sigma}{\sqrt n}} \end{aligned} \]
現在從母體平均數\(196\),母體標準差\(25\)抽出\(50\)個樣本,如果檢定統計量小於臨界值則拒絕\(H_0\),如果檢定統計量大於臨界值則不拒絕\(H_0\)。
# 隨機抽樣
sample_196 <- rnorm(50, mean = 196, sd = 25)
# 樣本平均數
mean(sample_196)#> [1] 198.0377# 檢定統計量
Z <- (mean(sample_196) - 200) / (25 / sqrt(50))
Z#> [1] -0.5550156# 檢定統計量有沒有落在拒絕域
## TRUE 則拒絕 H0,FALSE 則不拒絕 H1
Z < critical.value#> [1] FALSE第二種: 從信賴區間判斷
以左尾檢定為例,樣本平均數求得信賴區間的上界小於母體平均數,則拒絕 \(H_0\)。
# 信賴區間上界是否小於母體平均數
## TRUE 則拒絕 H0,FALSE 則不拒絕 H1
mean(sample_196) - qnorm(0.05) * 25 / sqrt(50) < 200#> [1] FALSE作業
請對資料的變數做假設檢定,並按照課本提到的六步驟回答。