預備
library(tidyverse)程式-卡方檢定
配適度檢定
以賽車手在不同賽道上的練習次數為例, Hamilton 在日本、新加坡、澳洲這三個國家的賽道上練習, 我們可能會想知道賽車手是否有偏好練習某條賽道, 猜想可能是因為賽道難度更高所以需要更頻繁的練習。 所以我們期望賽車手在三條賽道上的練習比例為 \(1:1:1\)。
假設檢定如下:
\[ \begin{aligned} \left\{ \begin{array}{ll} H_0: 賽道的練習次數和期望次數沒有顯著差異\\ H_1: 賽道的練習次數和期望次數有顯著差異 \end{array} \right. \end{aligned} \]
# 此題純屬虛構,請勿當真!!!
country <- c("Japan", "Singapore", "Australia")
times <- c(1259, 1382, 1541) # 次數
proportion <- times / sum(times) # 比例
proportion#> [1] 0.3010521 0.3304639 0.3684840卡方檢定的程式碼如下:
f1 <- chisq.test(times, p = c(1/3, 1/3, 1/3))
f1#>
#> Chi-squared test for given probabilities
#>
#> data: times
#> X-squared = 28.679, df = 2, p-value = 5.923e-07f1 有其他沒被 console 顯示的資訊,可以從 Global Environment 點選觀看,取值方式如下:
f1$observed#> [1] 1259 1382 1541f1$expected#> [1] 1394 1394 1394f1$residuals#> [1] -3.615783 -0.321403 3.937186獨立性
我們繼續上次做過的列聯表,但是換個方式解釋。列聯表表示五位駕駛以及他們在經過四條路線的次數。
driver <- c("Hamilton", "Bottas", "Verstappen", "Leclerc", "Vettle")
data <- tibble(driver = driver,
A = c(18, 16, 21, 23, 25),
B = c(17, 23, 21, 22, 24),
C = c(21, 23, 26, 29, 28),
D = c(22, 22, 22, 25, 28))
data#> # A tibble: 5 x 5
#> driver A B C D
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Hamilton 18 17 21 22
#> 2 Bottas 16 23 23 22
#> 3 Verstappen 21 21 26 22
#> 4 Leclerc 23 22 29 25
#> 5 Vettle 25 24 28 28資料需要轉換才能應用在畫圖。
data2 <- data %>%
gather(-driver, key = "road", value = "frequency") 畫圖的方式因人而異,只要能充分的傳達意思都是好圖。以下列舉幾種不同的做法。
把頻率用點的大小表現,
data2 %>%
ggplot(aes(road, driver)) +
geom_point(aes(size = frequency))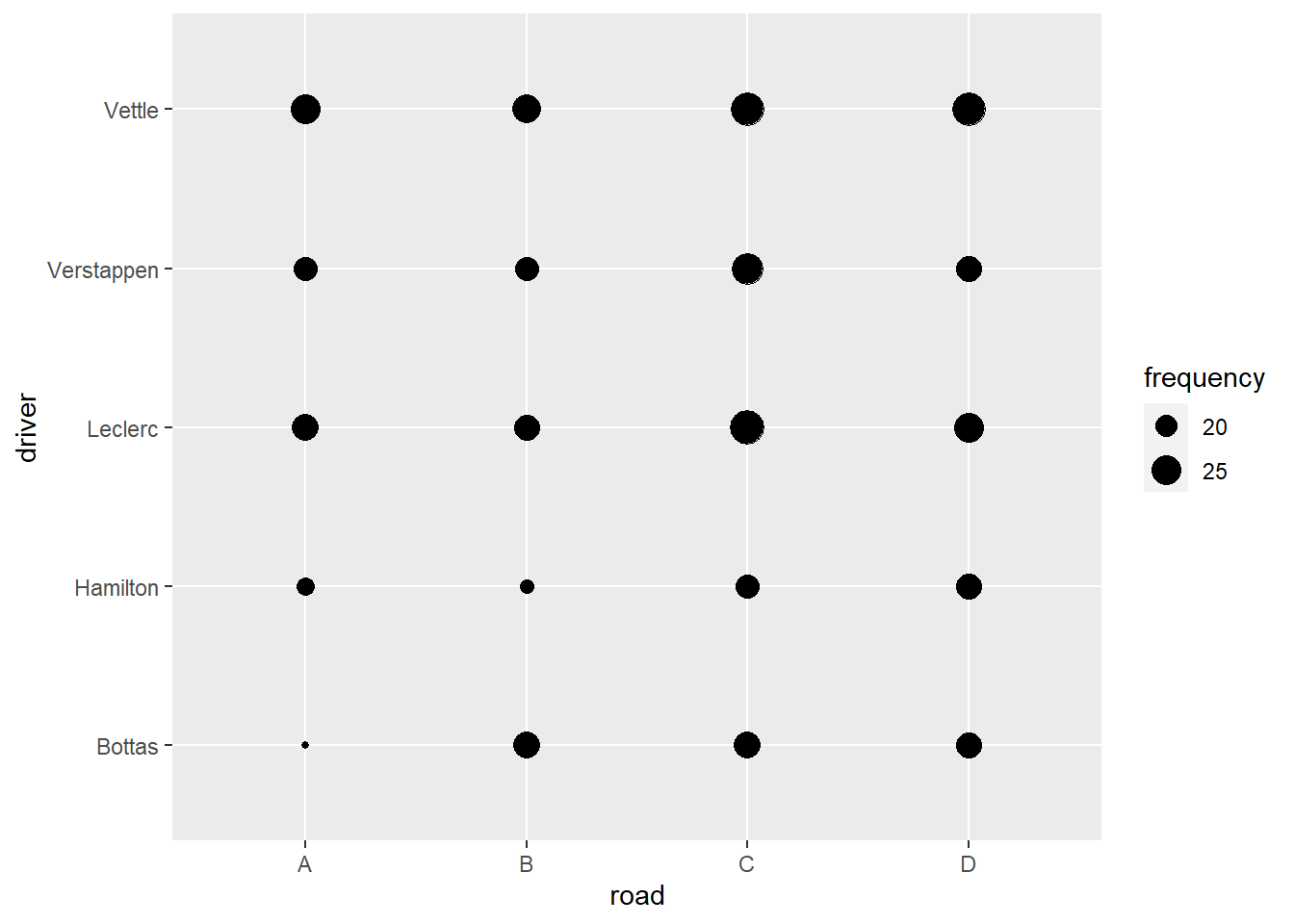
以次數的方式堆疊。
data2 %>%
ggplot(aes(driver, frequency)) +
geom_col(aes(fill = road))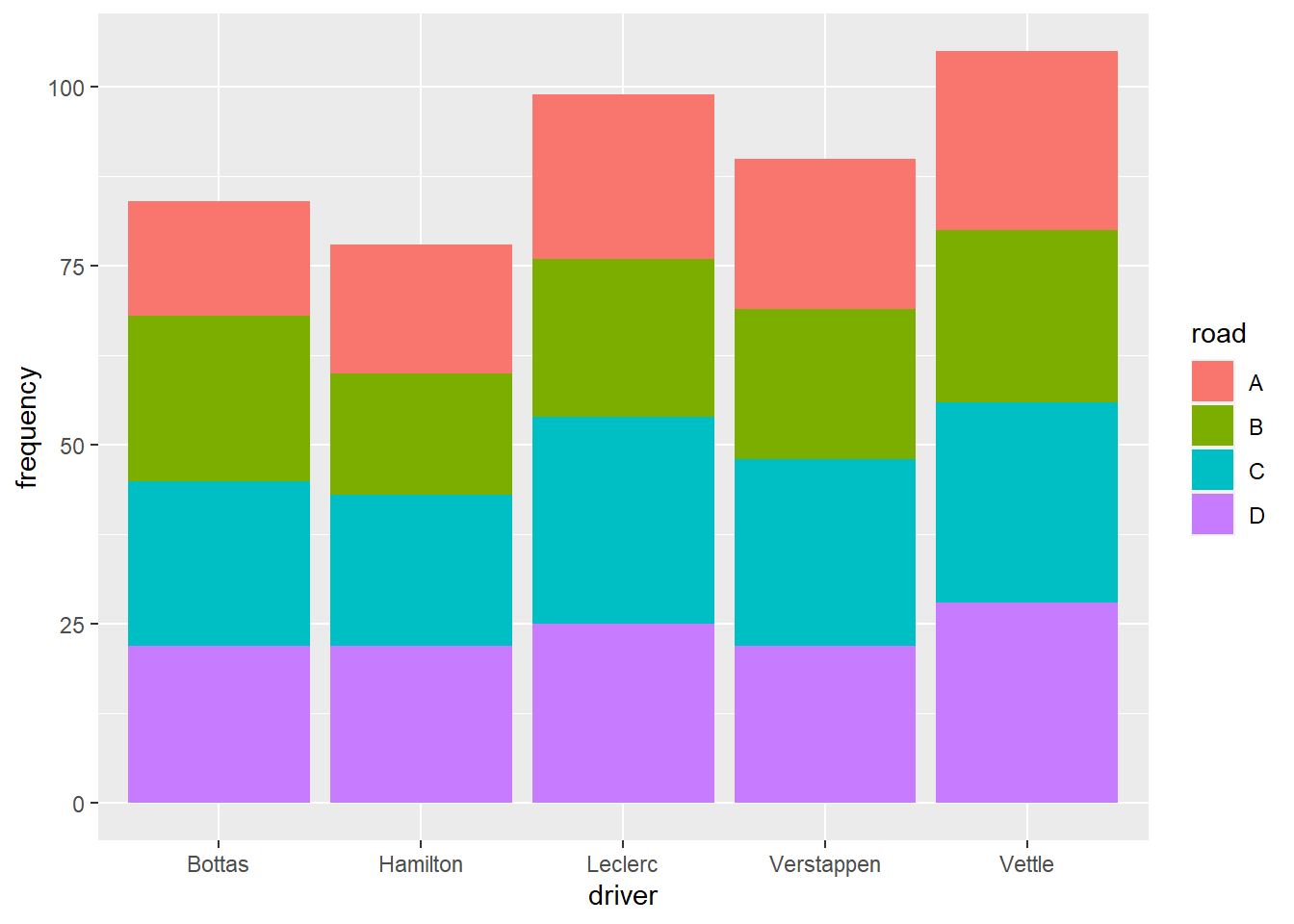
轉換成百分比的形式堆疊,
data2 %>%
ggplot(aes(driver, frequency)) +
geom_col(aes(fill = road), position = "fill")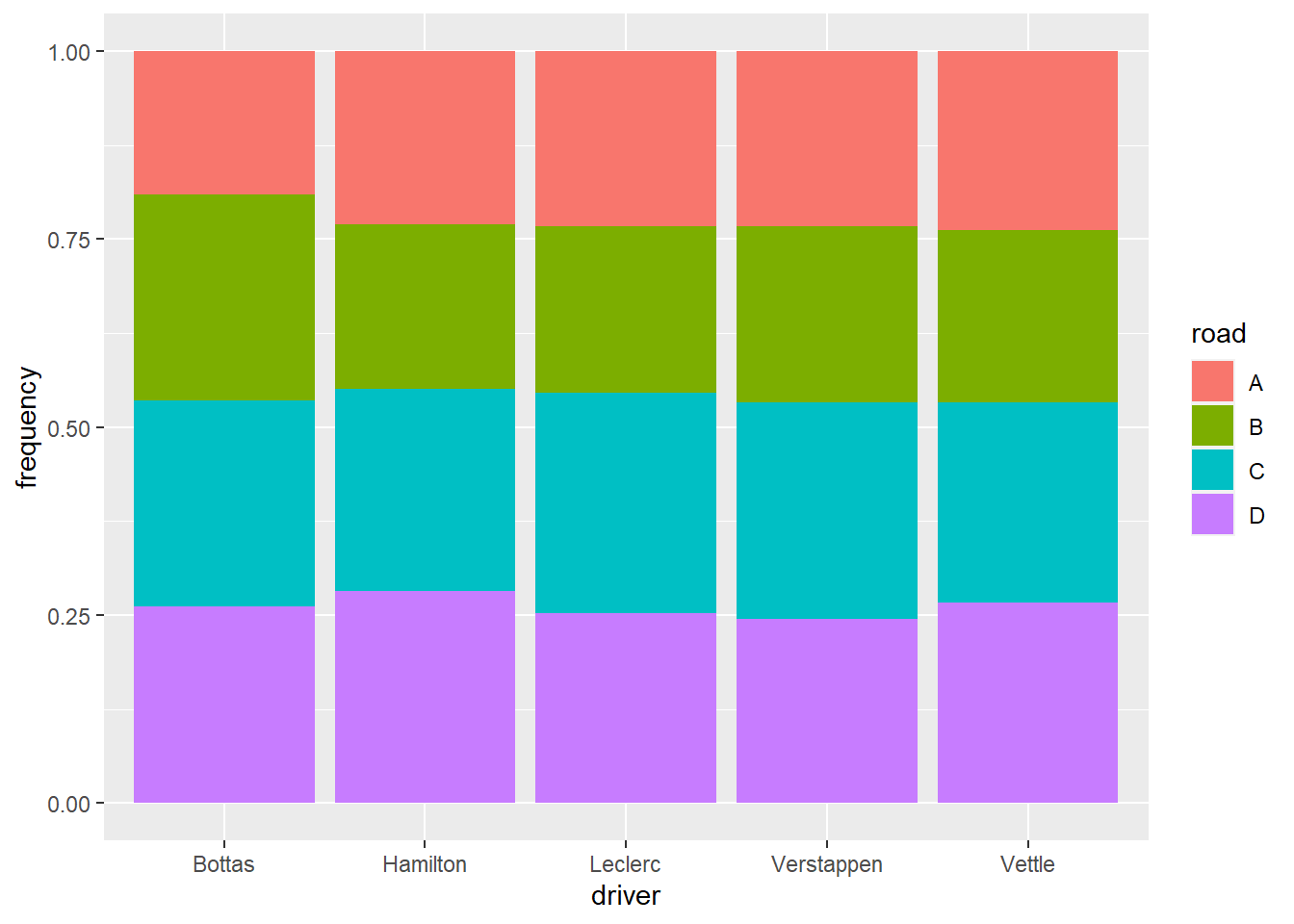
當然我們可以再加入更多的程式碼美化圖片,但在這之前,先練好基本型。
列聯表行列變數的獨立性檢定如下:
data2 <- data[,2:5]
data.chisq <- chisq.test(data2)
data.chisq#>
#> Pearson's Chi-squared test
#>
#> data: data2
#> X-squared = 1.7679, df = 12, p-value = 0.9997注意,chisq.test() 的資料要去掉變數名稱,
也就是只取列聯表的值當作資料。
data.chisq 有其他沒被 console 顯示的資訊,可以從 Global Environment 點選觀看,取值方式如下:
data.chisq$observed
data.chisq$expected
data.chisq$residuals程式-迴歸
我們又見到 mpg 了,以簡單線性迴歸為例,高速公路對市區油耗作圖如下,
ggplot(mpg, aes(cty, hwy)) +
geom_point() +
geom_smooth(method = "lm", level = 0.99)#> `geom_smooth()` using formula 'y ~ x'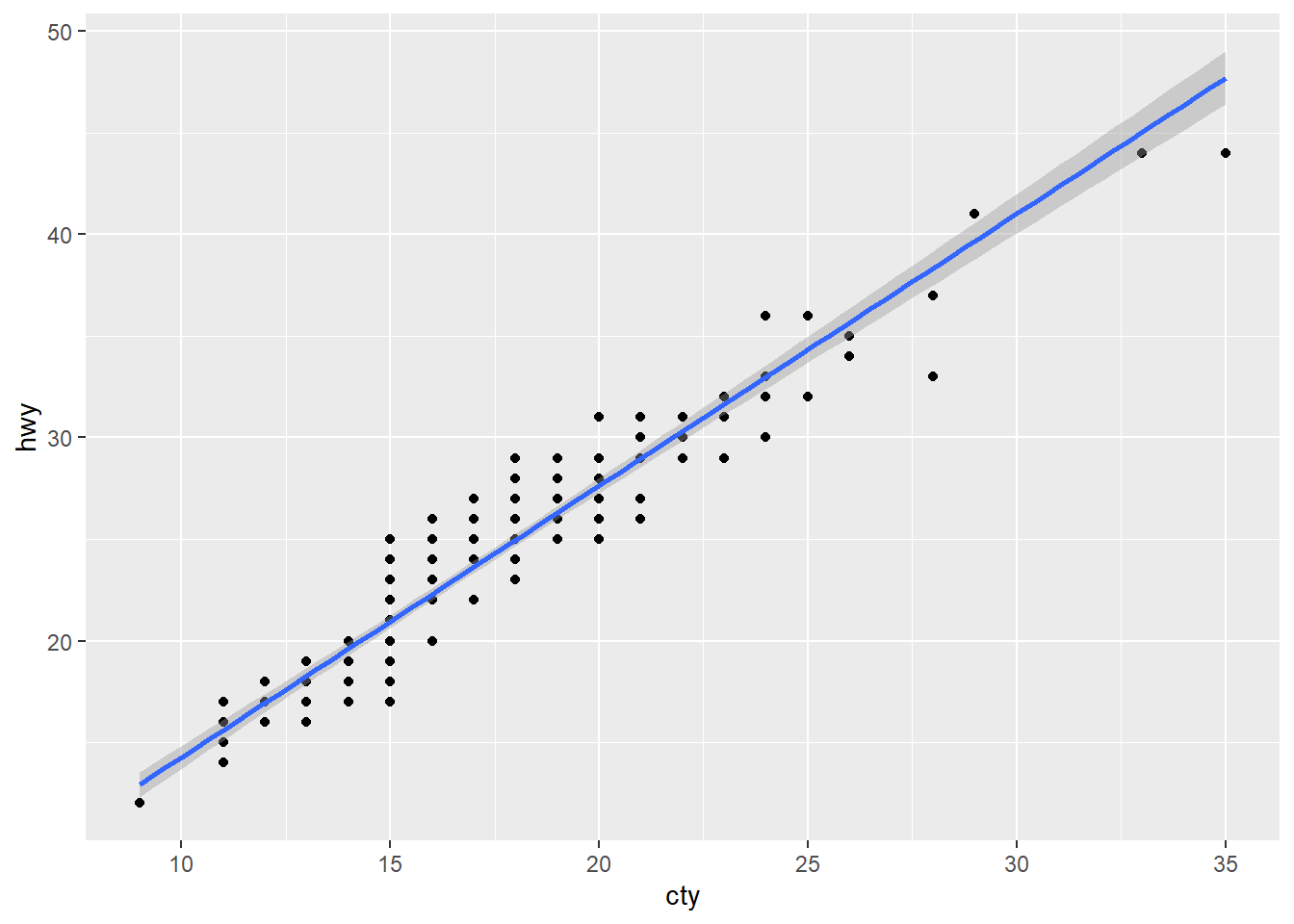
geom_smooth() 設定 method 為線性模型 lm,level 設定信賴區間的水準。如果不顯示信賴區間,設定 se = FALSE。
迴歸的程式碼如下,以 lm() 搭配 summary() 函數。
model <- lm(hwy ~ cty, mpg)
summary(model)#>
#> Call:
#> lm(formula = hwy ~ cty, data = mpg)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -5.3408 -1.2790 0.0214 1.0338 4.0461
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.89204 0.46895 1.902 0.0584 .
#> cty 1.33746 0.02697 49.585 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 1.752 on 232 degrees of freedom
#> Multiple R-squared: 0.9138, Adjusted R-squared: 0.9134
#> F-statistic: 2459 on 1 and 232 DF, p-value: < 2.2e-16如果要加入其他變數,只要用加法連接即可,如同 ANOVA 那節所述。
雖然我們可以不斷的增加新變數到模型去做預測, 但是要承擔型一誤差和型二誤差的風險。
\[ \begin{aligned} y = &\beta_0+\beta_1x_1+\beta_2x_2+\dots+e\\\\ &\left\{ \begin{array}{ll} H_0: & \beta_1 = 0\\ H_1: & \beta_1 \neq 0 \end{array} \right. \end{aligned} \]
我們可能會問某個變數種不重要,以\(95%\)信賴水準為例, 如果拒絕虛無假設,有\(5%\)的可能發生過度配適(overfitting); 如果不拒絕虛無假設,表示遺漏重要變數,產生偏差(bias)。 也就是我們面臨過度配適與偏差的權衡。
作業
練習卡方檢定以及迴歸模型。